인공지능(Artificial Intelligence)
: 사람의 지능을 만들기 위한 시스템이나 프로그램(딥러닝은 머신러닝에 포함되는 기술)
인공신경망
○ Node(노드) : 뉴런을 모방하는 기초단위
각각의 신경 단위에서 많은 입력을 조합해 하나의 출력값으로 배출
비선형 변환(활성 함수)을 통해 다음 노드에 전달
○ 피드 포워드(Feed-forwrad) 신경망 : 입력에서 출력으로 이어지는 과정에서 순환이 없는 신경망

○ 인공 뉴런(퍼셉트론)
* w : 가중치, b : 편향, h() : Activation Function


[이전에 책으로 공부하였던 내용 with keras]
2024.09.02 - [Networks/데이터 분석 및 AI] - SK networks AI Camp - 인공 신경망
SK networks AI Camp - 인공 신경망
Tensor Flow구글에서 만든 딥러닝 프로그램을 쉽게 구현할 수 있도록 기능을 제공하는 라이브러리모델 구축과 서비스에 필요한 다양한 도구를 제공, 신경망 모델을 빠르게 구성 가능한 Keras를 핵심
joowon582.tistory.com
딥러닝(Deep Learning)
○ 머신러닝 알고리즘 중 하나인 인공신경망을 다양하게 쌓은 것
○ 인공신경망을 여러 겹으로 쌓으면 딥러닝
○ 딥러닝은 머신러닝이 처리하기 어려운 비정형 데이터를 더 잘 처리
○ 단점
● 학습을 위한 많은 양의 데이터가 필요
● 계산 복잡 & 수행 시간 多
● 이론적 기반이 없어 결과에 대한 장담 X
● 블랙박스 접근 방식


○ 손실함수(Loss Function)
● 모델의 출력값(output)과 정답과의 오차(Error)
● 신경망이 학습할 수 있도록 해주는 지표
● 손실 값이 최소화되도록 하는 W(가중치), b(편향)를 찾는 것이 목표
○ 회귀(Regression)에서의 손실함수
● MSE(Mean Squared Error)
- L2 Loss
- 이상치에 민감
● MAE(Mean Absolute Errror)
- L1 Loss
- 이상치에 강건


○ 다중 분류(Multi-class Classification)에서의 손실함수
● CE(Cross Entropy) : 예측확률이 실제값과 얼마나 비슷한가를 측정


○ 이진 분류(Binary Classification)에서의 손실함수
● BCE(Binary Cross Entropy) : 이진 교차 엔트로피 손실
- y hat = 0과 1 사이의 연속적인 시그모이드 함수 출력값
- y = 불연속적인 실제값

- 단일 항목에 대한 BCE 공식

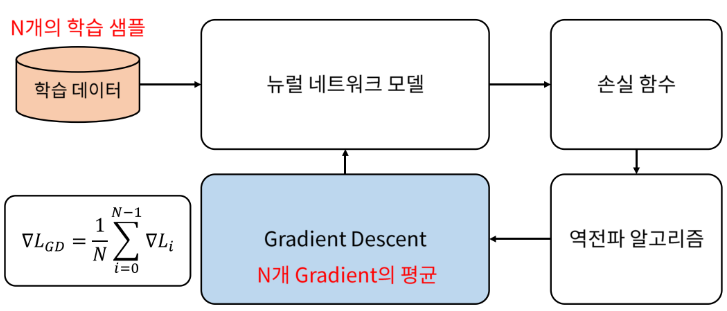
경사하강법(Gradient Descent)
: 모델이 잘 학습할 수 있도록 기울기(변화율)를 사용해 모델 파라미터를 조정하는 방법
● 과정
1. 예측과 실제값을 비교해 손실 구하기
2. 손실이 작아지는 방향으로 파라미터 수정
3. 과정 반복
● 경사(기울기) : 파라미터에 대한 오차의 변화
- 기울기 + : 파라미터 ↓(직선을 위로 올림; 왼쪽)
- 기울기 - : 파라미터 ↑(직선을 아래로 내림; 왼쪽)

● 학습률(Learning Rate) : 파라미터를 업데이트하는 정도를 조절하기 위한 값
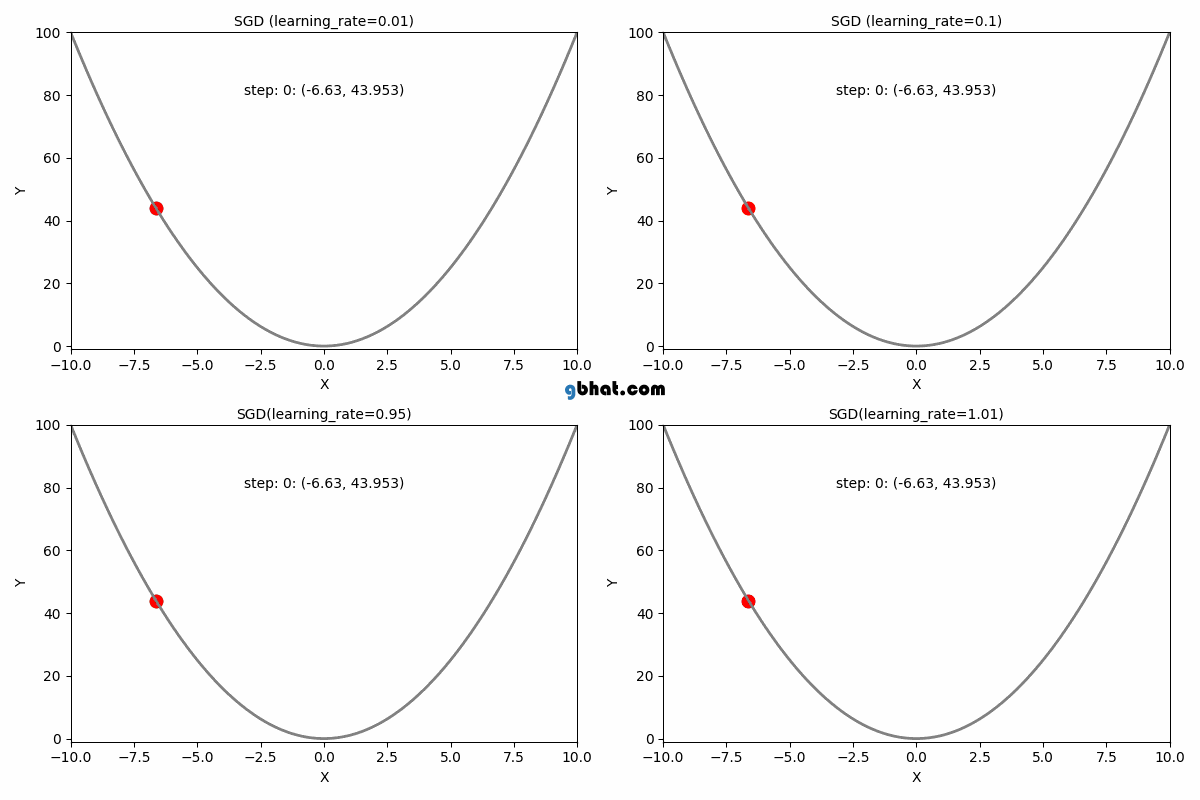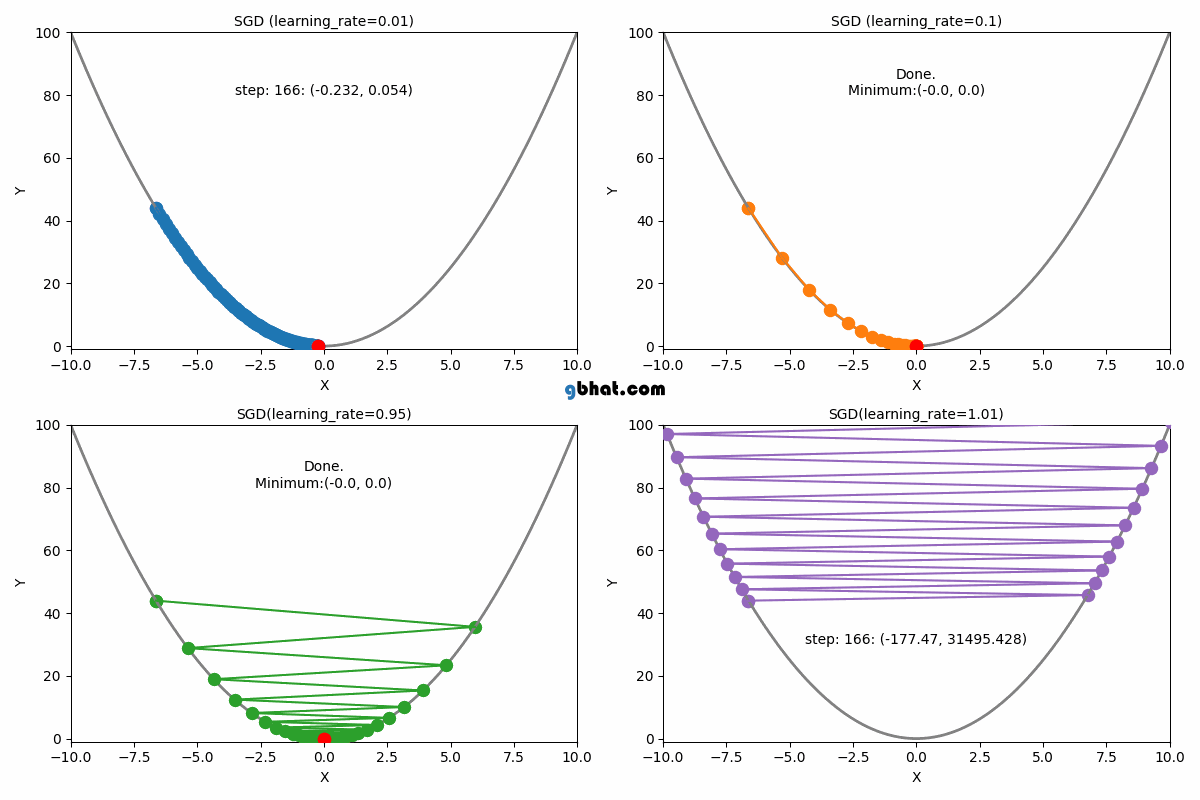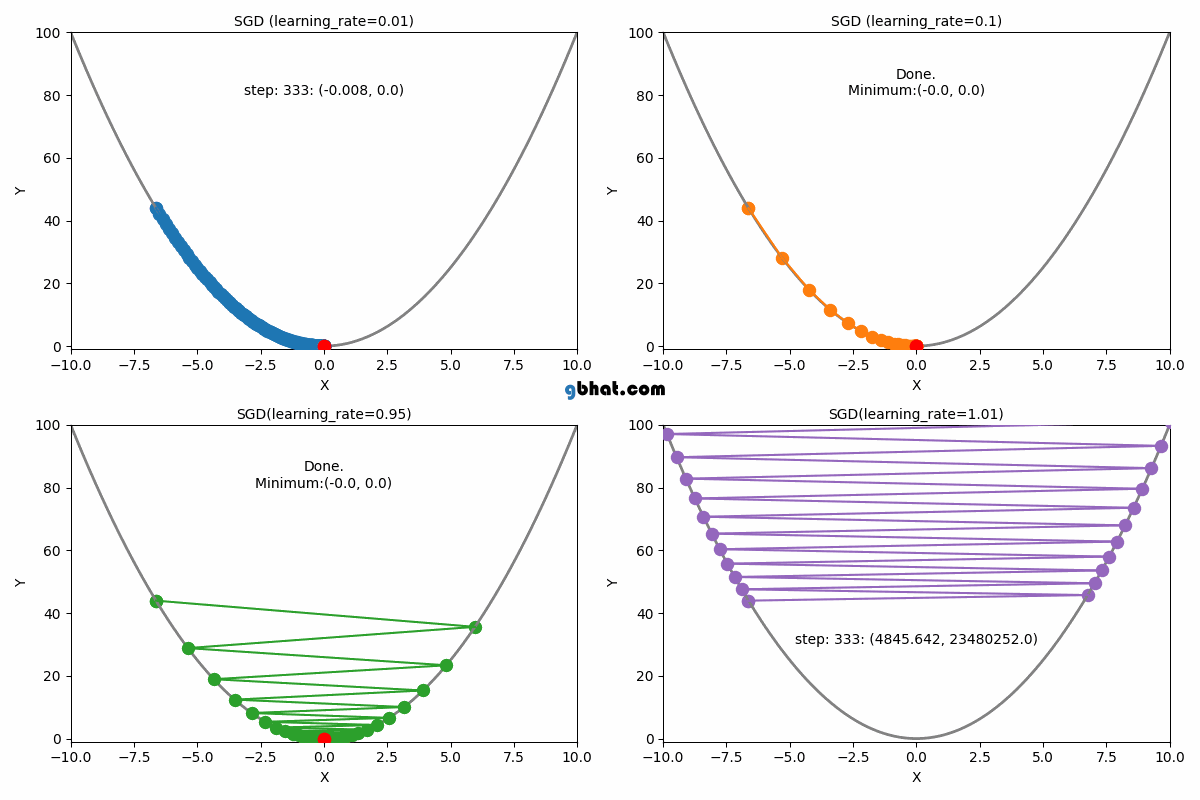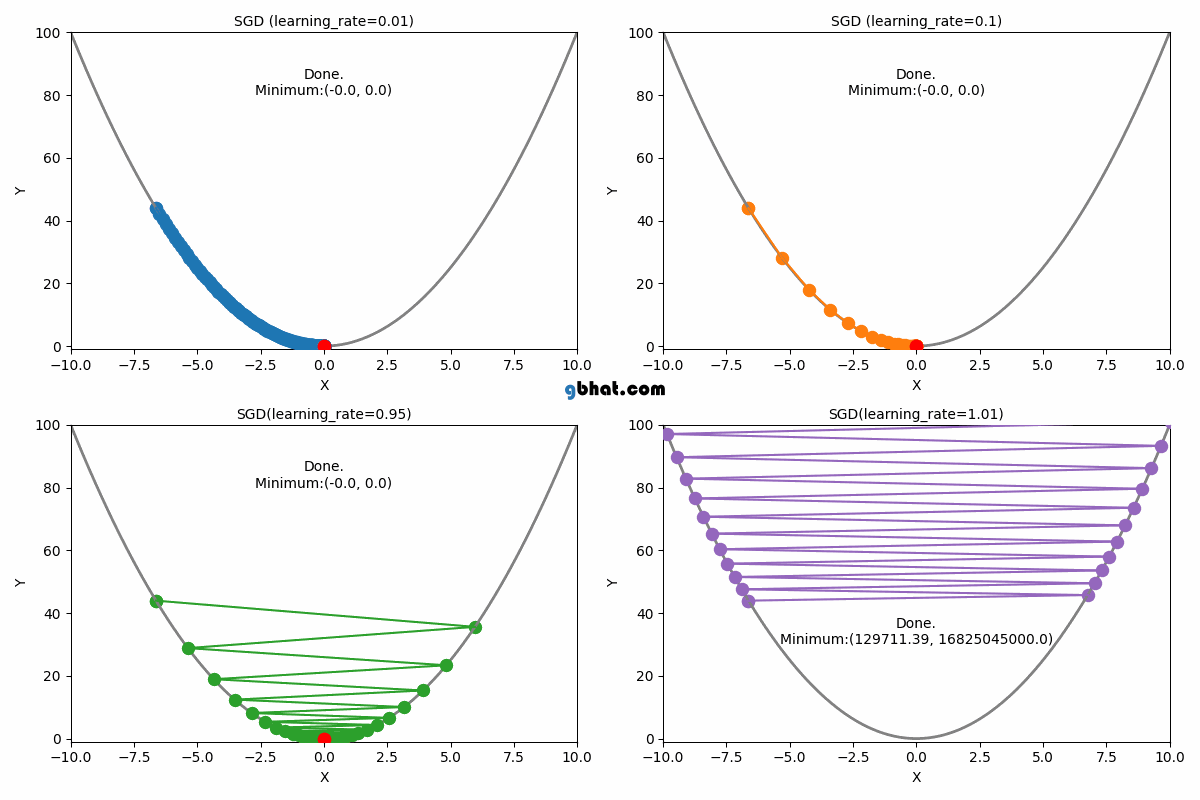
● 학습률이 너무 크거나 너무 작은 경우


역전파(Back-propagation)
: 손실값을 구해 이 손실에 관여하는 가중치들을 손실이 작아지는 방향으로 수정하는 알고리즘
● 효율적인 계산을 위해 사용
● 파라미터를 업데이트할 때 필요한 손실에 대한 기울기를 역방향으로 업데이트

기울기 소실 문제와 활성화 함수
: 층이 깊어지면서 역전파과정에서 가중치를 수정하려는 기울기가 중간에 0이 되어버리거나 0에 가깝게 작아지는
경사소실 문제가 발생
● 기울기 소실(Vanshing Gradient; 경사 소실)
: 딥러닝이 복잡해질수록 기울기 소실(= 오차가 발생했는데 반영이 안 되는 현상) 발생

● 기울기 소실 원인 : 활성화 함수의 기울기와 관련이 깊음
* 활성화 함수 종류 : Sign, Sigmoid, Tanh, Softmax, ReLU, Leaky ReLu 함수 등

e.g. Sigmoid
- X 값이 크거나 작아짐에 따라 기울기가 거의 0에 수렴
즉, Sigmoid 함수를 사용한 복잡한 딥러닝 모델은 학습이 잘 안 되게 된다.

● 기울기 소실 예시
- z1, z2, z3는 각 layer의 node의 출력과 가중치의 합성곱
- h1 ~ h3 : z1 ~ z3 값의 활성함수, sigmoid 함수 결과(= 각 노드의 출력)
- J의 출력이 최소화되도록 경사하강법을 통해 weight를 업데이트하기 위해 역전파 수행


● 해결방법
- ReLU는 Sigmoid와 다르게 기울기 소실 문제해결 가능 + 수식이 단순해 연산 속도도 빠름
- But ReLU는 음수는 반영이 안됨

배치(Batch)
: 한 번에 여러 개의 데이터를 묶어서 입력하는 것. GPU의 병렬연산 기능을 최대한 효율적으로 사용하기 위한 방법
○ Batch Gradient Descent
● 전체 데이터에 대해 error Gradient 계산
● 장점 : optimal로 수렴이 안정적
● 단점 : local optimal 상태가 되면 탈출이 힘듦
Gradient Descent 방법 : 일반적으로 gradient를 한번 업데이트하기 위해 모든 학습 데이터를 사용
(= 학습 데이터 전부를 넣어 gradient를 다 구하고 그 모든 gradient를 평균해서 한 번에 모델 업데이트)
대용량의 데이터를 한 번에 처리 못함 → 데이터를 batch 단위로 나눠서 하는 경우가 일반적
○ Stochastic Gradient Descent
● gradient를 한번 업데이트하기 위해 일부 데이터만을 사용(batch size만큼만 사용)
* 그림의 수식에서 B가 batch size
● 장점 : shooting이 일어나기에 local optimal에 빠질 위험이 적음
● 단점 : global optimal을 찾지 못할 가능성 존재

○ Mini-Batch Gradient Descent
● 장점 : BGD보다 local optimal에 빠질 위험이 적음
● 단점 : batch size를 설정해야 함

Epoch : 학습 데이터 전체를 학습한 단위
Batch : Gradient를 구하는 단위

Internal Covariant Shift
: Batch 단위로 학습하게 되면 학습과정에서 계층별로 입력 데이터 분포가 달라지는 현상
각 계층에서 입력으로 feature를 받고 그 feature는 convolution이나 fully connected 연산을 거친 후 af를 적용
* af : activation function
연산 전/후에 데이터 간 분포가 달라질 수 있음
유사하게 Batch 단위로 학습하면 Batch 단위 간 데이터 분포 차이 발생 가능
▷ Batch Normalization : 이 문제를 해결하기 위한 개념

Batch Normalization
: 학습 과정에서 각 배치 단위 별로 데이터가 다양한 분포를 가져도 각 배치별로 평균과 분산을 이용해 정규화하는 것
batch 단위나 layer에 따라 입력 값의 분포가 다르지만 정규화를 통해 zero mean gaussian 형태로 변환
→ 평균 = 0, 표준편차 1로 데이터 분포 조정 가능

Optimizer
: 미니배치 경사하강법 방식을 보완하고 학습 속도를 높이기 위한 알고리즘
● SGD(확률적 경사 하강법) : 랜덤 하게 추출한 일부 데이터를 사용해 더 빨리, 자주 업데이트하는 것(속도 개선)
● Momentum : 기존 업데이트에 사용했던 경사의 일정 비율을 남겨 현재의 경사와 더해 업데이트(정확도 개선)
● Adagrad : 각 파라미터의 update 정도에 따라 학습률 크기를 다르게 해 줌(보폭 크기 개선)
update가 지속됨에 따라 학습률이 점점 0에 가까워지는 문제 발생
● RMSProp : 이전 update 맥락을 보면서 학습률 조정하여 최신 기울기를 더 크게 반영(보폭 크기 개선)
● Adam : Momentum과 RMSProp 장점을 함께 사용(정확도 + 보폭 크기 개선)


정리
○ 미니배치학습을 위한 데이터셋을 구성
○ 딥러닝모델(인공신경망) 구현
○ 손실함수 : 해결하고자 하는 문제에 맞는 손실함수 사용
○ 옵티마이저 선택 : 경사하강법 문제 보완을 위함
○ 학습과정
● 데이터셋을 딥러닝 모델에 넣기
● 예측 결과에 대한 손실 구하기
● 역전파를 통해 모델 가중치의 기울기 구하기
● 옵티마이저를 이용해 모델 가중치 업데이트
'Networks > 데이터 분석 및 AI' 카테고리의 다른 글
| SK networks AI Camp - 합성곱 신경망 (2) | 2024.09.04 |
|---|---|
| SK networks AI Camp - 딥러닝 추가 조사 자료 (2) | 2024.09.04 |
| SK networks AI Camp - 인공 신경망 (3) | 2024.09.02 |
| SK networks AI Camp - 비지도 학습 (0) | 2024.08.31 |
| SK networks AI Camp- 회귀 (0) | 2024.08.30 |