0. Abstract
1. Introduction
2. Related Work
A. Recommender Systmes(RecSys)
B. From Pre-Trained Language Models(PLMs) to Large Language Models(LLMs)
3. Deep Representation Learning for LLM-Based Recommender Systems
A. ID-Based Recommender Systems
B. Textual Side Information-Enhanced Recommender Systems
4. Pre-Training & Fine-Tuning LLMs for Recommender Systems
A. Pre-Training Paradigm for Recommender Systems
B. Fine-Tuning Paradigm for Recommender Systems
5. Prompting LLMs for Recommender Systems
A. Prompting
B. Trustworthy Large Language Models for Recommender Systems
C. Vertical Domain-Specific LLMs for Recommender Systems
7. Conclusion
0. Abstract
○ RecSys는 사용자의 온라인 경험을 풍부하게 하기 위해 정보 과부하를 완화하는 데 중요한 역할
(= RecSys는 사용자가 관심 있는 정보를 찾기 위해 압도적인 필터링 과정을 생략해줌)
○ 추천 시스템의 기본 개념
● 사용자와 항목 간의 상호 작용 및 관련 사이드 정보(특히 항목 설명, 사용자 리뷰)를 활용해 사용자-항목 간 일치 점수
(= 사용자가 좋아할 확률)를 예측하는 것
○ DNN은 추천 시스템을 발전시키기 위해 널리 채택
● 다양한 아키텍처와의 사용자-항목 상호 작용을 모델링하는 고유한 기능을 보여줌
e.g. 사용자 상호 작용 시퀀스(순차 데이터에 특히 효과적)에서 고차 종속성을 캡처하기 위해 RNN 채택
e.g. If 사용자의 온라인 행동을 그래프 구조화된 데이터로 간주 → GNN 사용
● DNN은 사이드 정보를 인코딩하는 데에도 이점이 존재
e.g. BERT 기반 방법: 사용자로부터 텍스트 리뷰 추출 및 활용하기 위한 방법으로 제안

○ 하지만 여전히 대부분의 기존 고급 추천 시스템은 본질적 한계에 직면
1) 모델 규모 및 데이터 크기의 제한
● DNN기반(CNN 및 LSTM)모델과 추천 시스템용 사전 학습된 언어 모델(BERT)는 사용자 및 항목에 대한
텍스트 지식을 충분히 캡처할 수 없어 자연어 이해 능력이 열등
● So, 다양한 추천 시나리오에서 최적이 아닌 예측 성능을 제공
2) 대부분의 기존 ReSys방법은 자체 작업을 위해 특별히 설계 & 보이지 않는 권장 작업에 대한 일반화 기능 부족
● e.g. 영화의 평점 점수 예측을 위해 사용자 항목 등급 매트릭스에 대해 잘 훈련
But 이 알고리즘이 최고 등급을 수행하기 어려움
● why? Top-k와 함께 영화 추천
→ 권장 사항 아키텍처 설계가 특정 권장 사항 시나리오에 대한 작업별 데이터 및 도메인 지식에 크게 의존하기 때문
3) 대부분의 기존 DNN 기반 추천 방법은 간단한 결정이 필요한 추천 작업
● e.g. 등급 예측 및 top-k 권장 사항
● But 여러 추론 단계를 포함하는 복잡하고 다단계 결정을 지원하는 데 어려움 多
● e.g. 여행 계획 추천에서 다단계 추론
- 목적지 기반 인기 있는 관광 명소를 고려
- 관광 명소에 해당하는 적절한 일정 마련
- 특정 사용자 선호도(여행 비용 및 시간)에 따라 계획 추천
○ 최근 LLM이 NLP와 같은 다양한 연구 분야에 큰 영향을 미치고 있음
● 대부분 기존 LLM: 서면 자료와 같은 다양한 소스의 방대한 양의 텍스트 데이터를 사전 훈련한 트랜스포머 기반 모델
● LLM은 인간의 의도를 잘 이해하고 본질적으로 더 인간과 유사한 언어 응답 생성 가능
● 최근 연구: LLM은 인상적인 일반화 및 추론 능력을 보여 보이지 않는 다양한 작업 및 도메인으로 더 잘 일반화
(구체적: LLM은 각 특정 작업에 대해 광범위한 미세 조정을 요구하는 대신
적절한 지침 | 작업 데모 제공으로 학습한 지식과 추론 기술을 새로운 작업에 적용 가능)
● 컨텍스트 내 학습과 같은 고급 기술은 특정 다운스트림 작업에 대한 미세 조정 없이 LLM의 일반화 성능을 향상 가능
● 'Chain-of-Thought'와 같은 프롬프트 전략을 통해 권한을 부여받은 LLM은 복잡한 의사 결정 프로세스에서
단계별 추론을 통해 출력 생성 가능
● So, LLM은 강력한 기능을 감안할 때 추천 시스템을 혁신할 수 있는 큰 잠재력을 보여줌
○ 최근 LLM을 활용한 RecSys
● Chat-Rec
- ChatGPT와 대화 → 기존 RecSys에서 생성된 후보 세트를 개선 → 추천 정확도와 설명 가능성을 높이기를 제안
● Recommendation as instruction following
- T5를 LLM 기반 RecSys로 사용 → 사용자 RecSys 입력을 자연어로 명시적 선호도와 의도를 전달 가능하게 함
→ 단순 사용자-항목 상호 작용 기반으로 하는 것보다 더 나은 추천 성능을 보여줌
※ T5: Text-To-Text Transfer Transformer
● LLM의 급속한 발전으로 인해 LLM 기반 추천 시스템의 최근 발전과 과제를 종합적 검토는 필수적
○ 추천 시스템 영역의 기존 연구 요약
● 딥러닝 기술 관점에서 RecSys의 성능 촉진을 위해 다양한 초점이 검토됨(평가 방법론, 신뢰성, etc)
● LLM을 추천 시스템에 통합하는 것은 최근 연구에서 더 주목받는 분야
→ LLM 기반 추천 시스템의 학제 간 분야에서 새로운 트렌드와 고급 기술을 체계적으로 검토하는 것의 중요성 강조
● 추천 시스템에 대한 언어 모델링 패러다임 적응의 학습 전략과 학습 목표 검토
● But 주로 BERT 및 GPT-2와 같은 RecSys의 초기 단계 언어 모델 검토
● 차별적 관점과 생성적 관점에서 추천 시스템의 LLM을 요약
● 추천에서 고유한 기능에 맞게 조정된 두 가지 스타일의 LLM 비교
● 추천 시스템에서 LLM을 어디에, 어떻게 적용할 것인가라는 두 가지 직교적 관점을 소개
● 해당 연구에서는 RecSys의 파이프라인 제시, 권장사항을 통해 LLM의 다양한 기능을 검토
2. Related Work
○ RecSys, LLM 및 그 조합에 대한 몇 가지 관련 작업을 검토
[그림2]
● RecSys 및 LM(언어모델) 도메인을 정렬하기 위해 타임라인은 정확한 기간에 관계없이
기존 모델, 사전 학습된 LM/딥러닝 기반 모델, 색상으로 강조 표시된 LLM 시대의 3가지 단계로 구성

A. Recommender Systmes(RecSys)
○ 개인화된 추천 시스템
● 개인화된 콘텐츠와 서비스 제공으로 정보 과부하 문제 해결 및 다양한 온라인 application에서 중요한 도구로 부상
○ 대부분의 기존 권장 사항 접근 방식 범주
● CF(Collaborative Filtering)
● 콘텐츠 기반
○ CF 기반 추천
● 목표: 사용자의 유사한 행동 패턴을 찾아 향후 상호 작용 가능성 예측하기
● 구매 내역 또는 평점 데이터와 같은 사용자-항목 간의 과거 상호 작용 동작을 활용해 달성 가능
● e.g. CF 방법 중 하나인 MF(Matrix Factorization)
: 순수한 사용자-항목 상호 작용을 사용해 사용자 및 항목 표현을 학습하기 위해 도입
즉, 사용자 및 항목 고유 ID는 추천에 대한 일치 점수를 쉽게 계산 가능하도록, 벡터를 계속 포함하도록 인코딩됨
○ 콘텐츠 기반 추천
● 사용자 또는 항목에 대한 추가 지식(사용자 인구 통계 또는 항목 설명)을 활용해 추천 성능 개선하기 위해
사용자 및 항목 표현을 향상시킴
● Text 정보 = 사용자와 항목이 가장 많이 사용가능한 콘텐츠 So, 이 논문에서는 주로 Text에 중점
○ 뛰어난 표현 학습 능력으로 인해 딥러닝 기술은 추천 시스템 개발하는 데 효과적으로 적용됨
● e.g. NeuMF: 일반 내적을 DNN으로 대체 → 사용자와 항목 간의 비선형 상호 작용을 모델링하는 것이 좋음
● RecSys의 데이터가 그래프 구조화된 데이터로 표현될 수 있다는 점을 고려할 때,
GNN 기술은 RecSys에 대한 메시지 전파 전략을 통해 노드의 의미 있는 표현 학습을 위한 주요 딥러닝 방식으로 취급
● DeepCoNN: 사용자 및 항목에 대한 텍스트 지식 통합을 위해 CNN을 사용해 두 개의 병렬 신경망이 있는 항목에 대해
사용자 리뷰를 인코딩해 추천 시스템의 평가 예측에 기여하도록 제작
○ LLM의 발전으로 RecSys는 뉴스 추천과 같은 보다 개인화된 추천 제공 가능
● BERT4Rec: 사용자 행동의 순차적 특성을 모델링 하기 위해 BERT의 인코더 표현을 채택하기 위해 제안
● 트랜스포머의 언어 생성 기능을 활용하기 위해
트랜스포머 기반 프레임워크를 설계 → 추천 시스템에서 항목 추천과 설명을 동시 생성 가능
B. From Pre-Trained Language Models(PLMs) to Large Language Models(LLMs)
○ 일반적으로 언어 모델은 세 가지 주요 범주로 구분
(인코더 전용 모델, 디코더 전용 모델 및 인코더-디코더 모델)
1) 트랜스포머 아키텍처를 기반으로 하는 별개의 모델: BERT, GPT 및 T5
● BERT: 인코더 전용모델,
양방향 어텐션을 사용(각 토큰의 왼/오른쪽 컨텍스트를 모두 고려해 토큰 시퀀스 처리)
마스킹된 언어 모델링 및 다음 문장 예측 같은 작업 사용 → 텍스트 데이터 기반 사전 학습
→ 문맥에서 언어아 의미 뉘앙스 캡처
이러한 프로세스는 텍스트를 벡터 공간으로 변환해 미묘한 차이와 컨텍스트 인식 분석을 용이하게 함
● GPT: 트렌스포머 디코더 아키텍처 기반,
셀프 어텐션 메커니즘 사용(왼쪽 → 오른쪽 단방향 워드 시퀀스 처리를 위함)
언어 생성 작업, 임베딩 벡터를 텍스트 공간에 다시 매핑하고 컨텍스트 관련 응답 생성하는 데 채택
● T5: 인코더-디코더 모델
모든 자연어 처리 문제를 텍스트 생성 문제로 변환 → 모든 Text-To-Text 작업 처리 가능하게 함
모든 작업에 동일한 모델, 목표 및 훈련 절차 사용 So, 다양한 NLP 작업을 위한 다목적 도구가 됨
○ 최근 LLM은 ICL의 놀라운 기능을 보여줌
※ ICL: 설계와 기능의 핵심 개념,
사전 훈련을 통해 얻은 내부 지식에 의존하는 것 X → 입력 컨텐스트 기반 답변 이해와 제공하는 모델의 능력
● SG-ICL과 같은 다양한 작업에서 ICL의 활용을 탐구한 여러 연구가 존재
● 이러한 연구는 ICL을 통해 LLM이 일반적인 응답 생성 대신 입력 컨텍스트에 따라 응답 조정 가능성을 보여줌
○ CoT(Chain-of-Thought): LLM 추론 능력 향상 시킬 수 있는 기술
● 프롬프트 내에서 생각의 연쇄를 예제로 설명하기 위해 여러 데모를 제공하고 모델 추론 프로세스 안내까지 포함
● CoT의 확장: 답변에 대한 다수결 투표 메커니즘을 구현하여 작동하는 자기 일관성 개념
● 현재 연구: STaR과 같은 LLM에서 CoT의 적용에 대해 계속 탐구 중
○ RecSys에서 LLM의 주요 응용 프로그램(항목에 대한 사용자 등급 예측)
● 과거 사용자 상호 작용 및 선호도를 분석하여 달성 → 이를 통해 권장 사항의 정확성 향상
● TALLRec과 같이 사용자 상호 작용의 시퀀스 분석을 통해 다음 선호도를 예측하는 순차적 권장 사항에서도 사용됨
3. Deep Representation Learning for LLM-Based Recommender Systems
※ 이 장에서는 추천 시스템에서 언어 모델을 활용하는 두 가지 범주를 소개
○ RecSys에서 항목과 사용자를 나타내기 위해 간단한 방법
● 각 항목 또는 사용자에게 고유 인덱스 할당
● 사용자, 항목 = 추천 시스템의 원자 단위
○ ID 기반 추천 시스템
● 항목에 대한 사용자 선호도 포착을 위해 사용자-항목 상호 작용에서 사용자 및 항목의 표현을 학습하도록 제안
● 사용자 및 아이템에 대한 텍스트 사이드 정보는 사용자의 관심사를 이해할 수 있는 풍부한 지식을 제공
● So, 텍스트 사이드 정보 강화 추천 방법 개발
● Why? 추천 시스템에 대한 End-to-End 트레이닝 방식으로 사용자 및 아이템 표현 학습을 강화하기 위함
○ 그림 설명
● 개별 ID와의 사용자-항목 상호작용을 나타내는 ID 기반 표현
● 항목에 대한 사용자 리뷰와 같은 사용자 및 항목의 텍스트 측면 정보를 활용하는 텍스트 사이드 정보 강화 표현

A. ID-Based Recommender Systems
○ RecSys는 일반적으로 다양한 후보 항목에서 결정을 내리기 위한 사용자 행동에 영향을 주는 데 사용
● 사용자 행동(클릭, 좋아요, 구독)은 일반적으로 사용자-항목 상호작용으로 표시
● 사용자와 항목 = 별개의 ID로 표시
● 최신 권장 접근 방식: 각 ID 표현의 임베딩 벡터 학습 → 이러한 동작을 모델링하기 위해 제안
● 일반적으로, LLM 기반 추천 시스템에서, Item | 사용자는 아래와 같이 표현 가능
[prefix]_[ID]: prefix는 유형(항목 | 사용자), ID 번호는 고유성 식별에 도움
○ P5
● LLM 기반 방법의 초기 탐색으로 제안된 통합 패러다임
● 다양한 추천 데이터 형식의 전송을 용이하게 하기 위해 제안
● 사용자와항목(사용자-항목 상호 작용, 프로필, 사용자 리뷰)을 인덱스에 매핑 → 자연어 시퀀스로 변환
● 사전 학습된 T5 백본은 개인화된 프롬프트로 P5 학습하는 데 사용
● LLM의 어휘에서 이러한 인덱스를 특수 토큰으로 취급하기 위해 한 쌍의 꺾쇠 괄호와 함께 일반 인덱스 문구 통합
→ 문구를 별도의 토큰으로 토큰화하는 것을 방지
e.g. < item_6637>
● 순차적 인덱싱, 협업 인덱싱, 시맨틱(콘텐츠 기반) 인덱성, 하이브리드 인덱싱 등 인덱싱 방법의 중요성 강조
● P5: 각 사용자, 항목에 숫자 ID를 무작위로 할당
● 시맨틱 ID: 각 사용자, 항목에 대한 의미론적 의미를 가진 코드워드의 튜플
→ 각각 특정 사용자 또는 항목에 대한 의미론적 의미를 전달하는 고유 식별자 역할을 함
● RQ-VAE: 코드워드를 생성하기 위한 계층적 방법
추천 데이터 형식을 트랜스포머 기반 모델의 자연어 시퀀스로 효과적으로 변환 가능한 시맨틱 ID 활용
B. Textual Side Information-Enhanced Recommender Systems
○ ID 기반 방법은 본질적인 한계에 직면
● 사용자 및 항목의 순수 ID 인덱싱이 자연적으로 별개
● So, 권장 사항에 대한 사용자 및 항목의 표현을 캡처하여 충분한 의미 정보를 제공할 수 없기 때문
● 따라서 사용자-항목간 인덱스 표현을 기반으로 관련성 계산을 수행하는 것은 어려움
(특히, 사용자-항목 상호 작용이 심각하게 드문 경우 더욱 심화)
● 한편, ID 인덱싱은 일반적으로 어휘를 수정하고 LLM 매개변수를 변경 So, 추가 계산 비용이 발생
○ 대안 1. 사용자 및 항목의 텍스트 사이드 정보 활용
● 사용자 프로필, 항목에 대한 사용자 리뷰, 항목 제목 또는 설명 포함
● If 항목 | 사용자 텍스트 측면 정보가 주어지면
→ BERT와 같은 LM은 항목 또는 사용자를 의미 공간에 매핑하는 텍스트 인코더 역할 가능
● 여기에서 유사한 항목 또는 사용자를 그룹화하고 보다 세분화된 세분성으로 차이점 파악 가능
○ 대안 2. Unisec
● 항목 설명을 활용해 다양한 권장 사항 시나리오에서 전송 가능한 표현 학습하는 방법 中 1
● 파라메트릭 화이트닝 및 MoE(Mixture-of-Experts) 향상된 어댑터 사용
→ 범용 항목 표현을 인코딩하는 경량 항목 인코더도 도입
○ 대안 3. TCF(텍스트 기반 협업 필터링)
● GPT-3와 같은 LLM을 프롬프트하여 탐색
● 이전 ID 기반 협업 필터링과 비교했을 때, 긍정적인 성능을 보여줌
● 텍스트 사이드 정보 강화 추천 시스템의 잠재력 입증
○ 한계
● If LM에만 의존하여 항목 설명 인코딩 → 텍스트 기능이 과도하게 강조
[해당 문제를 완화하기 위한 방법]
● VQ-Rec 항목 텍스트를 개별 인덱스(항목 코드)의 벡터로 매핑
● 이를 사용하여 권장 사항의 코드 임베딩 테이블에서 항목 표현을 검색 가능한 벡터 양자화된 항목 표현 학습을 제안
● ZSIR(Zero-Shot Item-based Recommendation)을 위한 새로운 방법
● LLM에 PKG(Product Knowledge Graph)를 도입 → 아이템 기능 개선하는데 중점
● 사용자 및 항목 임베딩 = PKG에서 여러 사전 학습 작업을 통해 학습
[One4all User Representation for Recommender Systems in E-commerce :ShopperBert]
● 사용자 구매 내역 기반 여러 사전 학습 작업을 통해 사용자 임베딩을 사전 학습하는 전자 상거래 추천 시스템에서
사용자 표현을 나타내기 위한 사용자 행동 모델링 조사
● IDA-SR 순차 추천을 위한 ID에 구애받지 않는 사용자 행동 사전 학습 프레임워크는
BERT와 같은 사전 학습된 언어 모델을 사용하여 텍스트 정보의 표현을 직접 유지
○ 그림
[대표 방법 1]
● 시퀀스에서 토큰 또는 스팬을 무작위로 마스킹
● LLM이 나머지 컨텍스트 기반으로 마스킹된 토큰 또는 스팬을 생성하도록 요구하는 마스킹 언어모델
[대표 방법 2]
● 주어진 컨텍스트를 기반으로 다음 토큰에 대한 예측이 필요한 다음 토큰 예측의 관점에서 추천 시스템을 위한
사전 학습 LLM의 워크플로

○ 표 1: LLM 기반의 RecSys를 위한 사전 학습 방법
| 패러다임 | 방법 | 사전 학습 작업 |
| 사전 교육 | PTUM | 마스킹된 동작 예측 |
| Next K 행동 예측 | ||
| M6 시리즈 | 자동 회귀 생성 | |
| P5 시리즈 | 멀티태스킹 모델링 |
4. Pre-Training & Fine-Tuning LLMs for Recommender Systems
○ 추천 작업에서 LLM을 개발하고 배포하는 데 주요 방법(사전 학습, 미세 조정, 프롬프트)
● 해당 섹션: 그림 4, 그림 5에 각각 나와 있는 사전 학습 미세 조정 패러다임 소개
● 추천 시스템을 위해 LLM에 적용되는 특정 사전 학습 작업
& 다운스트림 추천 작업의 성능 향상을 위한 미세 조정 전략에 중점
○ 그림 5
● 전체 모델 미세 조정(Full-model Fine-Tuning): 전체 모델 가중치를 변경하는 방법
● 파라미터 효율적 미세 조정(Parameter-Efficient Fine-tuning)
: 대부분의 매개 변수를 수정하면서 모델 가중치의 작은 비율 | 몇가지 추가 학습 가능한 가중치를 미세 조정법

A. Pre-Training Paradigm for Recommender Systems
○ 사전 학습
● 전이 학습의 개념을 계승하는 LLM 개발의 중요한 단계
● 레이블이 지정되지 않은 텍스트 데이터로 구성된 방대한 양의 말뭉치에 대한 LLM 훈련이 포함
● 사전 학습을 통해 LLM은 다양한 언어적 측면(문법, 구문, 의미론, 상식적 추론)에 대한 광범위한 이해를 얻을 수 있음
● LLM은 일관되고 상황에 맞는 응답을 인식하고 생성하는 방법 학습 가능
● 자연어 처리 관점에서 LLM을 사전 학습시키는 두 가지 주요 패러다임이 존재
But 사전 학습 전략의 선택 = 특정 모델 구조에 따라 다름
○ 인코더-디코더 트랜스포머 구조의 경우
● MLM(Masked Language Modeling)이 널리 채택
● 시퀀스의 토큰 또는 스팬을 무작위로 마스킹
● LLM이 나머지 컨텍스트를 기반으로 마스킹된 토큰 또는 스팬을 생성해야 함
○ 사전 학습 디코더 전용 트랜스 포머 구조의 경우
● NTP(Next Token Prediction)를 사용하여 배포
● 지정된 컨텍스트 기반으로 다음 토큰에 대한 예측이 필요
○ 두 가지 사전 학습 과제
● 모두 조건문 완성을 포함
● But 접근 방식 차이
- MLM: 양방향 컨텍스트에서 마스킹된 토큰 예측
- NTP: 이전 컨텍스트만 고려
● 결론
- MLM: LLM이 토큰의 의미를 더 잘 이해하는 데 도움
- NTP: 언어 생성 작업에 더 자연스러움
○ 추천 시스템에서 기존 작업의 대부분은 고전적인 사전 학습 패러다임을 따름
● PTUM(두 가지 유사한 사전 학습 작업 제안)
- 사용자 행동 모델링을 위해 MBP(Masked Behavior Prediction) 및 NBP(Next K behavior Predicition) 사용
- 언어 토큰과 달리 사용자 행동은 다양 So, 예측하기 어려움
- PTUM은 토큰 범위를 마스킹하는 대신 대상 사용자의 상호 작용 시퀀스에 있는 다른 동작을 기반으로
마스킹된 동작을 예측하기 위해 단일 사용자 동작만 마스킹
- 반면, NBP는 사용자 모델링에 중요한 과거와 미래 행동 간의 관련성을 모델링
목표: 다음을 예측(k 사용자-항목 상호 작용 기록을 기반으로 하는 동작)
사용자 행동의 시간 시퀀스를 고려할 때, NBP는 자연스럽게 사용자를 시뮬레이션 → 더 나은 성능
● M6 시리즈
- 두 가지 고전적인 사전 학습 작업
(= 텍스트 채우기 목표와 자동 회귀 언어 생성 목표에 의해 동기 부여된 두 가지 사전 학습 목표)
1) 텍스트 채우기 목표: BART의 사전 학습 작업
텍스트 시퀀스에서 여러 토큰이 있는 범위를 무작위로 마스킹 & 마스킹된 범위를 사전 학습 대상으로 예측
→ 마스킹된 범위를 사전 학습 대상으로 예측
→ 권장 사항 점수 매기기 작업에서 Text | Event의 타당성 평가 기능 제공
BERT(Bidirectional Encoder Representations from Transformers)
: 구글에서 개발한 모델로, 양방향으로 문맥을 이해할 수 있는 최초의 NLP 모델 中 1
- 주요목표: 문장에서 각 단어의 문맥을 이해하기 위해 양방향 학습을 사용하는 것
- 주요 특징:
1) 양방향 학습
: 텍스트를 왼쪽 → 오른쪽 & 오른쪽 → 왼쪽으로 동시에 학습
문장의 모든 문맥을 고려할 수 있어, 보다 깊이 있는 언어 이해가 가능
2) 마스킹된 언어 모델링(Masked Language Modeling, MLM)
: 입력 문장에서 일부 단어를 무작위로 마스킹하고, 모델이 이 마스킹된 단어를 예측하도록 학습
→ 문장 내 단어들 간의 관계 학습 가능
3) 사전 학습 및 미세 조정
: 대규모 텍스트 코퍼스를 사용해 사전 학습을 거친 후, 특정 작업(예: 질문 답변, 감정 분석)에 맞게 미세 조정
BART (Bidirectional and Auto-Regressive Transformers)
: Facebook AI에서 개발한 모델로 BERT의 특징(양방향 인코더)과 GPT(자동 회귀 디코더)를 결합한 모델
다양한 텍스트 복원 작업에서 뛰어난 성능을 보이는 seq2seq 모델
- 주요 특징:
1) 결합된 아키텍처
: BERT와 GPT의 장점 결합
BERT의 양방향 인코더와 GPT의 자동 회귀 디코더를 함께 사용
→ 문맥을 이해하고, 새로운 텍스트를 생성하는 두 가지 작업에서 모두 뛰어난 성능 제공
2) 잡음 제거 자동 인코딩
: 입력 텍스트에 잡음을 추가 → 이를 원래 텍스트로 복원하는 방식으로 학습
이 방법은 모델이 다양한 텍스트 변형에 대해 강건해지도록 합니다.
3) 다양한 다운스트림 작업에 활용
: 텍스트 요약, 기계 번역, 텍스트 생성 등 다양한 NLP 작업에서 사용할 수 있도록 설계
2) 자동회귀 언어 생성 목표
- 자연어 사전 학습에서 NTP(Next Token Predictio) 작업을 따름
- But, 마스킹되지 않은 문장을 예측한다는 점에서 약간 다름
● P5
- 다중 마스크 모델링을 채택
- 사전 학습을 위해 다양한 추천 작업의 데이터 세트 혼합
- 다양한 추천 업무는 물론 제로샷 생성 능력으로 보이지 않는 업무까지 일반화 가능
- 다양한 권장 사항 작업에서 P5는 언어 시퀀스로 사용자 및 항목을 나타내기 위한 통합 인덱싱 방법을 적용
→ 마스킹 언어 모델링 작업을 사용할 수 있도록 함
B. Fine-Tuning Paradigm for Recommender Systems
○ 미세 조정
● 특정 다운스트림 작업을 위해 사전 훈련된 LLM을 배포하는 데 중요한 단계
● 특히, RecSys의 경우 LLM은 더 많은 도메인 지식을 파악하기 위해 미세 조정이 필요
● 사용자 및 항목에 대한 부수적인 지식(e.g. 사용자의 사회적 관계 및 항목 설명)을 포함하는
작업별 추천 데이터 세트를 기반으로 사전 학습된 모델을 학습하는 것이 포함
● 이 프로세스를 통해 모델은 권장 사항 도메인의 성능을 개선하기 위해 지식과 매개 변수 전문화를 할 수 있음
● 미세 조정 전략은 주어진 작업에 맞게 변경된 모델 가중치의 비율에 따라 두 가지 범주로 나눌 수 있음
1) 전체 모델 미세조정
● 특정 다운 스트림 권장 사항에 맞게 사전 훈련된 LLM을 배포하는 간단한 전략
e.g. RecLLM: LaMDA를 YouTube 동영상 추천을 위한 CRS(Conversational RecSys)로 미세 조정할 것을 제안
e.g. GIRL: LLM에게 작업 추천을 지시하기 위해 감독 미세 조정 전략을 활용
● LLM을 직접 미세 조정하면 추천 시스템에 의도하지 않은 편향 발생
2) 매개 변수 효율적인 미세 조정
● 전체 모델 미세 조정에서는 LLM의 크기가 확장됨에 따라 대규모 컴퓨팅 리소스가 필요
● 계산 비용을 고려, 특정 작업에 맞게 학습 가능한 어댑터를 개발하는 것이 목표
● PEFT(Parameter-Efficient Fine-Tuning)는 전체 모델 미세 조정과 비슷한 성능을 달성하기 위해
LLM에서 대부분의 매개 변수를 수정 + 모델 가중치의 작은 부분 또는 몇 가지 추가 학습 가능한 가중치 조정을 포함
● 가장 있기있는 PEFT 방법 = 추가 훈련 가능한 가중치를 어댑터로 도입하기
※ 어댑터 구조는 LLM의 트랜스포머 구조에 임베딩하기 위해 설계됨
※ 각 트랜스포머 레이어에 대해 어댑터 모듈이 두 번 추가됨
1) 첫 번째 모듈: 멀티 헤드 어텐션 → 투영 → 추가
2) 두 번째 모듈: 두 개의 피드 포워드 레이어 뒤에 추가
● 미세 조정 중에 사전 훈련된 LLM의 원래 가중치는 고정
● 어댑터와 레이어 정규화 레이어는 다운스트림 작업에 맞게 밋 조정
→ 어댑터는 LLM의 혹장 및 일반화에 기여 So, 전체 모델 미세 조정 및 치명적 망각 문제를 완화
● LoRA(Low-Rank Adaptaion of LLMs)
- LLM의 가중치 행렬의 어댑터와 낮은 내재 순위에 대한 아이디어에서 영감을 받음
- 파라미터의 변화를 시뮬레이션하기 위해 낮은 순위의 분해를 도입
- LLM의 원래 구조에서 행렬 곱셈을 처리하는 특정 모듈에 대한 새로운 경로를 추가
- 경로에서 두 개의 직렬 행렬: 먼저 차원을 중간 계층의 미리 정의된 차원으로 줄이고 다시 차원을 늘림
이 경우 중간 레이어 차원 = 고유 순위를 시뮬레이션 가능
● RecSys에서 PEFT는 추천 작업을 위해 LLM을 미세 조정하는 계산 비용을 크게 줄일 수 있음
+ 업데이트가 덜 필요 + 대부분의 모델 기능 유지 가능
5. Prompting LLMs for Recommender Systems
○ 그림 6
● LLM을 프롬프트하는 워크 플로
● (Method1) LLM의 파라미터 업데이트가 필요없는 In-Context Learing
● (Method2) LLM에 새로운 프롬프트 토큰 추가
→ LLM의 입력 레이어에서 최소한의 파라미터 업데이트와 함께 프롬프트 최적화를 하는 Prompt Tuning
● (Method3) 여러 작업별 프롬프트에 대해 LLM을 미세조정하는 Instruction Tuning

○ 프롬프트는 작업별 프롬프트를 통해 LLM을 특정 다운스트림 작업에 적용을 위한 최신 패러다임 역할 수행
● 프롬프트는 LLM 입력에 적용할 수 있는 텍스트 템플릿을 나타냄
● e.g. "The relation between _ and _ is _." 프롬프트: 관계 추출 작업을 위해 LLM을 배포하도록 설계 가능
● 프롬프트를 통해 LLM은 다운스트림 작업을 언어 생성 작업으로 통합 가능 + 사전 학습 중에 목표에 맞게 조정됨
○ 추천을 위한 LLM 성능을 촉진하기 위한 프롬프트 최근 연구
● ICL(In-Context Learning) 및 CoT(Chain-of-Thougt)
: 추천 작업을 위한 프롬프트를 수동으로 설계하기 위한 기술 연구
● LLM에 프롬프트 토큰 추가 → 작업별 추천 데이터 세트 기반으로 업데이트하여 프롬프트를 추가하는 기술 역할 수행
● 사전 학습 미세 조정 패러다임과 프롬프트를 결합한 명령튜닝
: 명령 기반 프롬프트를 사용해 여러 추천 작업에 걸쳐 LLM을 미세조정하는 방법을 탐구하며
보이지 않는 권장 작업에 대한 LLM의 제로샷 성능을 향상 시킴
A. Prompting
○ 프롬프트의 핵심 아이디어
● LLM을 고정(= 파라미터 업데이트 없음)하고 작업별 프롬프트를 통해 LLM을 다운스트림 작업에 맞게 조정하는 것
● 초기 단계의 기존 프롬프트 방법
: 주로 텍스트 요약, 관계 추출, 감정 분석과 같은 언어 생성 방식으로 다운스트림 작업을 통합하는 것이 목표
● 이 후 ICL는 LLM이 컨텍스트 정보를 기반으로 새로운 작업을 학습할 수 있도록 하는 강력한 프롬프트 전략
● CoT라는 또 다른 최신 프롬프트 전략이 존재
● 이는 LLM이 복잡한 추론으로 다운스트림 작업을 처리하도록 유도하는 데 특히 효과적인 방법
A-1 기존 프롬프트: 작업 성능 개선을 위해 미리 학습된 언어 모델을 프롬프트 하는 두 가지 주요 접근 방식
● 프롬프트 엔지니어링
: 언어 모델이 사전 학습 중에 접한 텍스트를 에뮬레이트하여 프롬프트 생성
→ 사전 학습된 언어 모델은 보이지 않는 목표가 있는 다운스트림 작업을 알려진 목표가 있는 언어 생성 작업으로 통합
● 입력-출력 프롬프트
: 입력-출력 예제를 제공해 특정 다운스트림 작업에 대해 원하는 출력을 생성하도록 프롬프트하고 안내하는 방법
A-2 ICL(In-Context Learning;상황 내 학습)
● ICL은 많은 다운스트림 작업에 적응할 때 LLM의 성능을 크게 향상시키는 고급 프롬프트 전략으로 제안
● ICL의 성공은 프롬프트 및 컨텍스트 내 데모라는 두 가지 설계에 기인
(ICL의 핵심 혁신: 추론 단계에서 컨텍스트에서 다운스트림 작업 학습을 위해 LLM의 컨텍스트 내 기능 이끌어내기)
● ICL에서 제안된 두 가지 설정은 RecSys에 대한 LLM을 프롬프트하는 데 널리 활용됨
1) few-shot 설정
- 특정 다운스트림 작업의 컨텍스트 및 원하는 완료가 포함된 데모가 프롬프트와 함께 제공되는 설정
2) Zero-shot 설정
- LLM에 데모가 제공되지 않고 특정 다운스트림 작업에 대한 자연어 설명만 프롬프트에 추가됨
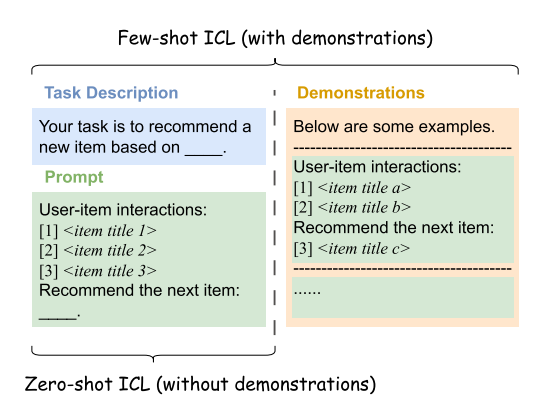
○ 기존의 많은 연구들
● 동일한 추천 과제 하에서 성과 비교를 위해 few-shot ICL과 zero-shot ICL 설정을 동시에 고려
● 일반적으로 Few-Shot ICL은 LLM에 추가적인 컨텍스트 내 데모 제공 So, 제로샷 ICL 능가 가능
● 성능 저하에도 Zero-Shot ICL은 컨텍스트 내 데모 형성을 위한
작업별 추천 데이터 세트의 요구 사항을 완전히 완화하고
사용자가 LLM에 데모를 제공할 가능성이 없는 대화형 권장 사항과 같은 특정 작업에 적합할 수 있음
○ ICL을 통해 LLM을 추천 작업에 적용하기 위한 간단한 접근 방식
● LLM이 추천자 역할을 하도록 가르치기
e.g. ChatGPT를 사용하고 Top-K 추천, 등급 예측, 설명 생성 등 다양한 추천 작업에 맞는 별도의 작업 설명 제안
→ 각 추천 작업의 해당 입출력 예시 기반으로 ICL 수행(e.g. 사용자 평점 기록은 평점 예측 작업의 예로 제공)
○ LLM이 RecSys 역할을 직접 하도록 가르치는 것 외에 활용
● ICL이 LLM과 기존 추천 모델을 연결하는 데 활용
e.g. Chat-Rec라는 프레임 워크가 있음 → ICL을 통해 ChatGPT와 기존 RecSys를 연결하는 것이 제안
→ ChatGPT는 기존 RecSys에서 후보 항목을 수신하는 방법 학습 → 최종 추천 결과 구체화
+ 외부 그래프 추론 도구용 텍스트 API 호출 템플릿 설계
+ ICL을 통해 해당 템플릿을 사용해 외부 도구에서 생성된 그래프 기반 추천 결과에 액세스하도록 가르침
※ 최근 InteRecAgent와 같은 RecSys에서 사용자 동작 시뮬레이션을 위해 LLM 기반 자율 에이전트 개발됨
※ RecAgent 및 Agent4Rec LLM에 메모리 및 액션 모듈 장착
A-3 CoT(생각의 사슬) 프롬프트
○ ICL은 컨텍스트 내 데모를 통해 다운스트림 작업에 대한 LLM을 유도하는 데 큰 효과를 보임
But LLM은 추론이 많은 작업에서 여전히 제한된 성능을 보임
● 입-출력 쌍의 컨텍스트 내 예제를 LLM에 표시하면 LLM이 직접 생성하는 답변이 종종 어려움을 겪음
● 1단계 누락 오류: 하나 또는 몇 개의 추론 단계 누락, 수학 방정식과 같은 다단계 문제에서
후속 추론 단계에서 오류를 유발하는 추론 논리가 손상됨
● RecSys에도 유사한 다단계 문제 존재
(like 대화 권장 사항의 다중 턴 대화 상자 기반으로 하는 사용자 기본 설정의 다단계 추론)
● 한계 해결을 위해 CoT는 프롬프트에 중간 추론 단계에서 주석을 달기
→ LLM의 추론 능력을 향상시키는 프롬프트 전략 제공
→ LLM은 복잡한 의사 결정 프로세스 세분화 & 단계별 추론을 통해 최종 출력 생성 가능
○ Zero-Shot CoT
● 프롬프트에 "단계별로 생각해 봅시다" 및 "그러므로, 답은 다음과 같습니다"와 같은 까다로운 텍스트 삽입
→ 독립적으로 작업별 추론 단계를 생성하도록 유도
○ Few-Shot CoT
● ICL의 각 데모에 대해 작업별 추론 단계가 수동으로 설계됨, 원래의 입-출력 예제는 입-CoT-출력 방식으로 증강
● CoT는 작업별 지식을 기반으로 추론 단게에 대한 해석 가능한 설명 추가 → ICL 데모에서 작업 설명 보강 가능
○ 실제 적절한 CoT 추론 단계의 설계는 특정 권장 작업의 컨텍스트와 목표에 따라 크게 달라짐
e.g. 간단한 CoT 템플릿"Please ferer the preference of the user and recommend suitable items"
→ LLM이 먼저 사용자의 명시적인 선호도 추론 → 최종 추천 생성 제안
e.g. 전자 상거래 권장 사항 맥락에서의 CoT 프롬프트 예시
[CoT 프롬프트] 사용자 구매 내역을 기반으로 차근차근 생각해 봅시다. 먼저 사용자의 높은 수준의 쇼핑 의도를 유추해 보세요. 둘째, 일반적으로 구매한 품목과 함께 구매하는 품목은 무엇입니까? 마지막으로 쇼핑 의도에 따라 가장 관련성이 높은 품목을 선택하여 사용자에게 추천하십시오.
○ 최근 연구(InteRecAgent)
● RecMind CoT 프롬프트 사용 → LLM이 Agent 역할 & 외부 도구를 활용하기 위한 계획을 생성
● 복잡한 권장 사항을 하위 작업으로 관리하도록 함
B. Prompt Tuning
○ LLM에 새로운 프롬프트 토큰 추가 → 태스크별 데이터 세트 기반 프롬프트 최적화하는 기술로 사용
● 프롬프트 수동 설계에 비해 작업별 지식과 인적 노력이 덜 필요
● 조정 가능한 프롬프트와 LLM의 입력 레이어에 대한 최소한의 파라미터 업데이트만 포함
e.g. (AutoPrompt) Prompt를 어휘 토큰 집합으로 분해 → 특정 작업의 성능과 관련해 그레디언트 기반 검색
→ LM에 적합한 토큰을 찾기
B-1 Hard Prompt Tuning
● LLM을 특정 다운스트림 작업에 프롬프트하기 위해 프롬프트 개별 텍스트 템플릿 생성 & 업데이트
※ ICL은 하드 프롬프트 튜닝의 일부로 간주할 수 있다고 주장
● ICL은 작업별 추천 데이터 셋 기반으로 자연어로 프롬프트 구체화
→ LLM을 다운스트림 추천 작업에 프롬프트 하기 위한 하드 프롬프트 튜닝 수행
● But 자연어 프롬프트 구체화 및 편리함에도 이산 최적화 문제에 직면 할 수밖에 없음
※ 특정 추천 작업에 적합한 프롬프트를 찾기 위해 방대한 어휘 공간을 발견하기 위해 힘든 시행착오를 겪는 것
B-2 Soft Prompt Tuning
● 연속 벡터를 프롬프트(e.g. text Embedding)로 사용
● 그래디언트 메서드를 사용해 권장 사항 손실과 관련해 프롬프트 업데이트하는 등 작업별 데이터 셋 기반 최적화
● LLM에서 소프트 프롬프트 토큰은 종종 입력 계층의 원래 입력 토큰(e.g. 토크나이저)에 연결됨
● 소프트 프롬프트 튜닝 중에는 LLM의 입력 레이어에 있는 소프트 프롬프트와 최소 파라미터만 업데이트 됨
C. Instruction Tuning
프롬프트 LLM은 보이지 않는 다운스트림 작업에서 놀라운 퓨샷 성능을 보여주었지만, 최근 연구에 따르면 프롬프트 전략은 제로샷 능력이 훨씬 떨어지는 것으로 나타났습니다.
이러한 한계를 해결하기 위해, 여러 작업별 프롬프트에 대해 LLM을 미세 조정하기 위한 명령어 튜닝이 제안됩니다. 즉, 명령어 조정은 프롬프트 및 사전 학습 미세 조정 패러다임의 기능을 모두 가지고 있습니다.
이를 통해 LLM은 다양한 다운스트림 작업에 대한 지침으로 프롬프트를 정확히 따르는 더 나은 기능을 얻을 수 있으며, 따라서 새로운 작업 지침을 정확하게 따름으로써 보이지 않는 작업에 대한 LLM의 향상된 제로샷 성능에 기여합니다.
명령어 튜닝의 핵심 인사이트는 특정 다운스트림 작업을 해결하는 대신 프롬프트를 작업 지침으로 따르도록 LLM을 훈련시키는 것입니다. 좀 더 구체적으로 말하자면, 인스트럭션 튜닝은 "인스트럭션"(즉, 프롬프트) 생성과 모델 "튜닝"의 두 단계로 나눌 수 있는데, 인스트럭션 튜닝의 간단한 개념은 프롬프트와 미세 조정 LLM의 조합이기 때문입니다.
• 명령(프롬프트) 생성 단계
. 공식적으로 명령어 조정은 작업 지향 입력(즉, 작업별 데이터 세트를 기반으로 한 작업 설명)과 원하는 대상(즉, 작업별 데이터 세트를 기반으로 한 해당 출력) 쌍으로 구성된 자연어의 명령 기반 프롬프트 형식을 도입합니다.
다운스트림 추천 작업을 위한 LLM의 명령어 튜닝을 고려하여, 사용자 선호도, 의도 및 작업 양식을 포함한 권장 사항 중심의 지침 템플릿을 제안하며, 이는 다양한 권장 작업에 대한 지침을 생성하기 위한 공통 템플릿 역할을 합니다. 보다 직접적으로, "작업 설명-입력-출력" 형태의 세 부분으로 구성된 지침 템플릿이 사용됩니다.
작업별 권장 사항 데이터 세트를 기반으로 지침을 생성합니다.
• 모델 튜닝 단계
. 두 번째 단계는 앞서 언급한 다운스트림 작업에 대한 여러 명령어에 대해 LLM을 미세 조정하는 것으로, LLM의 미세 조정 방식(전체 모델 튜닝 및 파라미터 효율적인 모델 튜닝)에 따라 RecSys의 기존 작업을 분류합니다.
예를 들어, LoRA를 활용하여 다운스트림 추천 작업을 위해 LLaMA의 명령어 튜닝을 보다 가볍게 만듭니다.
RecSys의 텍스트 데이터 외에도 최근 추천 작업을 위한 LLM의 그래프 이해 능력을 향상시키기 위해 명령어 튜닝이 연구되고 있습니다. 특히, 행동 그래프의 노드(예: 후보 항목)와 에지의 경로(예: 항목 간의 관계)를 자연어 설명으로 인코딩하는 LLM 기반 프롬프트 생성자를 제안하며, 이는 이후에 작업별 데이터 세트를 기반으로 LLM 기반 추천자를 조정하는 데 사용됩니다.
6. Future Directions
○ 해당 연구에서 LLM으로 향상된 RecSys에 대한 최신 고급 기술을 종합적으로 검토함
○ RecSys에 대한 LLM 적용은 아직 초기 So, 많은 과제가 존재하며 이는 기회일 수 있음
A. Hallucination Mitigation
○ LM은 실제로 부정확 | 입력 데이터에서 참조할 수 없는 출력을 생성하는 '환각' 현상이 중요한 과제
● 데이터 세트에 존재하는 소스-참조 발산과 같은 다양한 신경망 모델의 학습 및 모델링 선택 때문
● 해결을 위해 RecSys용 LLM의 학습 및 추론 단계에서 사실적 지식 그래프를 보충적, 사실적 지식으로 사용하여 완화
● 출력 단계를 조사하여 제작된 콘텐츠의 정확성과 사실성 확인 가능
B. Trustworthy Large Language Models for Recommender Systems
○ 신뢰성 부족한 의사 결정, 불평등 대우, 투명성/설명 가능성 부족, 개인 정보 보호 문제 등이 위협 가능
● So, RecSys용 LLM은 아래를 포함한 4가지 차원에서 신뢰성을 확보하고자 함
- 안정성 및 견고성(Safety & Robustness)
- 비차별성(Non-discrimination) 및 공정성(Fairness)
- 설명 가능성(Explainability)
- 프라이버스(Privacy)
B-1 Safety & Robustness
○ 안전이 중요한 Applicatiion에서 안정성 견고성을 손상시킬 수 있는 적대적 섭동에 취약
※ 적대적 섭동 예시: 입력의 사소한 변경
● 모델 안정성과 견고성 강화를 위해 GPT-4는 RLHF 중에 안전 관련 프롬프트를 통합
※ RLHF: Reinforcement Learning from Human Feedback
○ RLHF는 수동 라벨링을 위해 상당한 수의 전문가 필요 & 실제 실현 가능하지 않을 수 있음
● 대안: LLM에 입력하기 전에 Rec 작업을 위해 설계된 프롬프트의 자동 사전 처리가 포함될 수 있음
● + 악의적인 프롬프트에 대한 사전 처리 또는 유사 목적을 가진 프롬프트가 동일한 최종 입력을 갖도록 표준화
→ 안전성과 견고성 향상 가능
B-2 Non-Discrimination & Fairness
○ LLM은 종종 의도치 않게 인간 데이터의 편견과 고정관념을 학습, 영속화 → 추천 결과에 드러날 수 있음
● 특정 사용자 그룹에 대한 불공정한 대우에 이르기까지 다양한 부정적 결과 초래 가능
B-3 Explainability
○ 개인 정보 보호,보안으로 ChatGPT 및 GPT-4와 같은 고급 LLM을 오픈 소스로 제공하지 않기로 결정
● RecSys용 LLM의 아키텍쳐와 매개변수가 대중이 복잡한 내부 작업 메커니즘을 이해할 수 없음
● RecSys용 LLM은 '블랙박스'로 취급 가능
B-4 Privacy
[생략]
C. Vertical Domain-Specific LLMs for Recommender Systems
○ 일반 LLM(ChatGPT 등)는 생성 및 추론 기능을 통해 다양한 영역에서 보편적인 도구가 됨
○ 버티컬 도메인별 LLM: 특정 도메인 또는 산업에 맞게 훈련되고 최적화된 LLM
○ 최근 기존 작업에서 의료와 같은 광범위한 영역을 포괄하는 수직적 도메인별 LLM 제시
● But 모델 학습을 위해 방대한 양의 도메인별 데이터 필요 So, 데이터 수집 및 주석에 상당한 문제 발생 가능
○ So, 고품질 도메인 데이터 세트를 구성하고 특정 도메인에 적합한 튜닝 전략이 필요
e.g. Amazon-M2라는 다국어 데이터 세트를 Amazon의 세션 기반 추천의 새로운 설정으로 제안
+ LLM을 RecSys로 활용
→ 다양한 언어의 사용자 세션 그래프에서 다국어 및 텍스트 데이터가 포함된 세션 그래프에서 학습할 수 있는 기회 제공
D. User & Items Indexing
○ 긴 텍스트에서 User-Item 상호 작용 정보를 효과적으로 캡처하기 어려울 수 있음
● So, RecSys에서 긴 텍스트 처리 시 LLM이 제대로 작동하지 않을 수 있음
○ 반면 RecSys에서 고유한 ID를 사용한 User-Item 상호작용은 풍부한 협업 지식 포함
● 평점 및 리뷰와 같은 명시적 행동 + 검색 기록 또는 구매 데이터와 같은 암시적 행동을 모두 포함
→ 사용자 선호도 이해 및 예측에 큰 기여
○ 긴 텍스트 문제 해결을 위한 해결책
● User-Item 상호작용 통합 → 공동 지식 학습을 위해 User 및 Item 인덱싱 수행
E. Fine-Tuning Efficiency
○ RecSys에 LLM을 적용할 때 미세 조정 = 사전 훈련된 LLM을 특정 작업 | 도메인에 적용하는 프로세스
● But 미세 조정은 추천 시스템의 매우 큰 모델 및 대규모 데이터 세트의 경우 계산 비용이 많이 들 수 있음
● So, 미세 조정 효율성 개선이 핵심 과제
○ 미세 조정 효율성 개선 방법
● 기본 모델과 별도로 최적화 가능한 작은 플러그인 신경망(어댑터 모듈) 사용 → 파라미터의 효율적인 전이 학습 달성
● But RecSys에 대한 현재 어댑터 튜닝 기술: 플랫폼 간 이미지 추천과 관련해 전체 모델 미세 조정보다 뒤쳐짐
● So, 멀티모달 RecSys에 대한 어댑터 튜닝 효과 탐구는 잠재적인 미래 방향
+ End-To-End 교육을 통해 RecSys의 계산 비용과 시간을 줄일 수 있는 효과적인 최적화 기술 탐색도 중요
F. Data Augmentation
○ RecSys 분야의 대부분의 기존연구
● 사용자 상호 작용 또는 어노테이터 모집을 통한 사용자 행동 데이터 수집 기반으로 하는 실제 데이터 기반 연구에 의존
● 그럼에도 이러한 접근 방식은 리소스 집약적 & 장기적으로 지속 불가 할 수 있음
○ 데이터 중심 연구 단점 극복을 위한 방법
● RecAgent: LLM 기반의 RecSys을 위한 시뮬레이션 패러다임
● LLM-Rec
- 개인화된 콘텐츠 추천을 개선하기 위해 4가지 프롬프트 전략 통합
- 다양한 프롬프트 및 입력 증강 기술이 추천 성능 향상을 할 수 있음을 실험을 통해 보여줌
※ So, LLM을 RecSys로만 배치하는 것이 아니라 데이터 증강에 활용 → 추천을 강화하는 것이 유망한 전략
7. Conclusion
○ LLM을 통해 RecSys를 혁신하여 고품질의 개인화된 제안 서비스 제공을 위한 노력 증가 中
○ 기존 LLM 기반 Recsys을 포괄적으로 요약하는 체계적인 개요가 절실히 필요
○ RecSys의 LLM에 대한 연구는 아직 초기 So, 이 분야의 LLM에 대한 보다 체계적, 포괄적인 연구가 필요
'Networks > 논문 리뷰' 카테고리의 다른 글
| [논문리뷰] Self-Attentive Sequential Recommendation (1) | 2024.12.28 |
|---|---|
| [논문리뷰] Neural Collaborative Filtering (0) | 2024.11.17 |
| [논문리뷰] DeepFM: A Factorization-Machine based Neural Network for CTR Prediction 리뷰 및 프로젝트 (5) | 2024.11.15 |