개요
○ 선형회귀모델 1
○ 선형회귀모델 2
○ 선형회귀모델 3
○ 선형회귀모델 4
● 분산분석
선형회귀모델 1 - 선형회귀모델 개요
[변수 사이의 관계]
○ X변수(원인)과 Y변수(결과) 사이의 관계
● 확정적 관계: X변수만으로 Y를 100% 표현(오차항 X)
- Y = f(X)
e.g. 힘 = f(질량, 가속도), 주행거리 = f(속도, 시간)
● 확률적 관계: X변수와 오차항이 Y를 표현(오차항 O)
- Y = f(X) + ε
e.g. 반도체 수율 = f(설비 파라미터들의 상태, 온도, 습도) + ε
e.g. 포도주 가격 = f(온도, 포도 품종) + ε
e.g. 위조카드 여부 = f(사용기간, 사용액, 사용장소) + ε
○ 선형회귀 모델
● 출력변수 Y를 입력변수 X들의 선형결합으로 표현한 모델
● 선형결합: 변수들을 (상수 배와) 더하기 빼기를 통해 결합
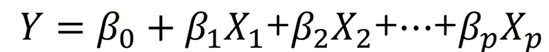
● X변수 한 개가 Y를 표현하는 경우: Y = B0 + B1X(직선 식)

○ 선형회귀 모델링의 목적
● X 변수와 Y변수 사이의 관계를 수치로 설명
● 미래 반응변수(Y)값을 예측
○ 선형회귀모델 분류
● X변수의 수, X변수와 Y변수의 선형성 여부에 따라 구분

선형회귀모델1 - 선형회귀 모델 가정



선형회귀모델2 - 파라미터 추정(최소제곱법)
○ 파라미터 추정 예시
● 1번 직선이 2번 직선보다 점들을 잘 표현한다고 볼 수 있음
● 1번 직선에서 점들과의 차지의 모든 합을 더하면? 0
● 차이가 최소가 되는 y절편과 기울기를 찾고자 함


● 알고리즘을 사용하여 \hat{B0}, \hat{B1}을 찾고 식을 찾는 전체적인 과정 = 모델링

○ 파라미터 추정 알고리즘
● 선형회귀 모델에서 Cost function is Convex→ globally optimal solution exists(전역 최적해 존재)
● So, 기울기가 0이 되는 곳까지 찾음 → 각 점에서 미분값이 0이 되는 B0, B1의 값을 찾음
→ 비용함수가 최소가 되는값을 찾게 됨
※ 최적의 파라미터 표현을 위해 hat을 적어준거

○ 파라미터 추정 알고리즘 과정
Question: Find estimator of B0 and B1 (i.e. , \hat{B0} and \hat{B1})
● step1) 실제 y값과 직선에 있는 점사이의 차이의 제곱 구하기
● step2) 비용함수를 최소화시키는 B0과 B1 구하기
● step3) 비용함수가 convex 형태 So, 미분한 값이 0(= 기울기가 0)이 되는 지점 구하기
Algorithm: Least Squares Estimation Algorithm(최소제곱법, 최소자승법)

○ 잔차(Residual)
※ 표기: e
● 최소제곱법으로 구한 직선 위에 있는 점과 실제 y값의 차이
● 잔차 e는 확률 오차 ε 이 실제로 구현된 값(왼쪽: 잔차, 오른쪽: ε)

○ 선형 회귀 모델 예제
● The regression equation is
Appraised Value(집 가격) = -29.6 + 0.0779Area(집크기)
※ \hat{B0} = -29.6, \hat{B1} = 0.0779
● 집 크기가 1 square feet 증가할 때마다 집 가격은 0.077($ thousand, $77) 증가



선형회귀모델3 - 파라미터 추론(구간추정, 검정)
○ 추정량
● Estimator(추정량): 샘플의 함수(a function of the samples) e.g. \hat{B0}, \hat{B1}
● 추정량 용도: 알려지지 않은 파라미터 추정(B0, B1)
● 추정량 종류: 점추정, 구간추정
○ 점추정(Point Estimator)

○ 최소제곱법 추정량 성질
● Gauss-Markov Theorem: Least Square estimator is the best linear unbiased estimator(BLUE)
● BLUE: The BLUE is
(1) Unbiased estimator and
(2) has the smallest average squared error(variance) compared to any unbiased estimators

○ 파라미터에 대한 구간추정
● 점추정은 하나의 값으로 추정하게됨

● 구간추정: 구간으로 추정하여 보다 유연한 정보 제공
θ(파라미터)에 대한 구간추정 기본 형태
● 알아야 하는 값: 점추정량값, 점추정량에 대한 표준편차, 상수값

○ 기울기에 대한 신뢰구간

○ 기울기에 대한 가설 검정
● 알려지지 않은 파라미터에 대한 가설을 세우고 이를 검정
● 일종 오류 α 하에서 기울기가 0인지 아닌지 검정
● IF 검정 통계량이 크다 = 귀무가설에서 주장이 실제 데이터와 괴리가 크다 So, 기각

○ 선형회귀 모델 예제
※ estimator = function, estimates = 값
● 파라미터: B0, B1
● 파라미터에 대한 추정치: Coef의 값(\hat{B0} = -29.59, \hat{B1} = 0.077939)
● 파라미터에 대한 standard error(점 추정량에 대한 표준편차): SE Coef 값
● T 값: 검정 통계량
● P 값: 두 번째 아래 오른쪽 그림
● S 값: σ 점추정량 값




선형회귀모델4 - 결정계수(R^2)
○ 결정 계수(Coefficient of Determination: R^2)
● SSR/SST = 1 이라면? 에러가 하나도 없음 → SSE = 0 → 점들이 직선 위에 전부 존재한다.(확정적 관계)
● SSR/SST = 0 이라면? SSR = 0 → X를 사용하여 y값을 설명했을 때 아무 소용이 없다는 뜻
● R^2 = SSR/SST = 1 - SSE/SST
● 즉, R^2은 0과 1 사이에 존재
● R^2 = 1: 현재 가지고 있는 X 변수로 Y를 100% 설명(즉, 모든 관측치가 회귀직선 위에 있다)
● R^2 = 0: 현재 가지고 있는 X 변수는 Y 설명(예측)에 전혀 도움이 되지 않는다.
● R^2 = 사용하고 있는 X 변수가 Y 변수의 분산을 얼마나 줄였는지 정도
= 단순히 Y의 평균값을 사용했을 때 대비 X 정보를 사용함으로 얻는 성능향상 정도
= 사용하고 있는 X 변수의 품질

○ 수정 결정계수(Adjusted R^2)
● R^2은 유의하지 않은 변수가 추가되어도 항상 증가
● So, 수정 R^2은 앞에 특정 계수를 곱해줌으로(보정) 유의하지 않은 변수가 추가될 경우 증가하지 않게 함
● 설명변수가 서로 다른 회귀모형의 설명력을 비교할 때 사용

○ 선형회귀 모델 예제
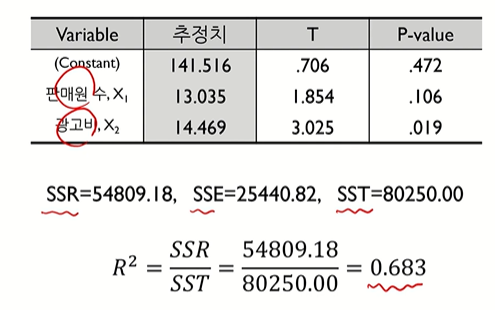
● 전국적으로 500개의 대리점을 가지고 있는 요플레 제조회사에서 각 대리점의 판매원수와 광고비 지출이
매출액에 어떤 영향을 미치는가를 알아보기 위해 10개의 대리점에 대한 자료 수집

● 판매원 수와 광고비 변수에 의해 매출액 변수의 변동성을 68.3% 감소
● 매출액의 (단순)평균 대비 판매원 수와 광고비를 이용하면 설명력이 68.3% 증가
● 현재 분석에 사용하고 있는 판매원 수와 광고비의 "변수 품질"정도가 68.3(100점 기준)
선형회귀모델4 - 분산분석
○ 분산분석: Analysis of Variance(ANOVA)
● 분산 정보를 이용하여 분석
● 궁극적으로 가설검정을 행하는 용도로 사용

○ 선형회귀모델에서의 분산분석
● 얼마나 커야 큰 값? 분포를 알면 통계적으로 판단 가능 But 직접적으로 분포를 정의 불가
● But SSR과 SSE가 각각 카이제곱 분포(파라미터: 자유도)를 따름(2번째 그림)



○ 테이블로 정리(단순 회귀 모델의 경우)
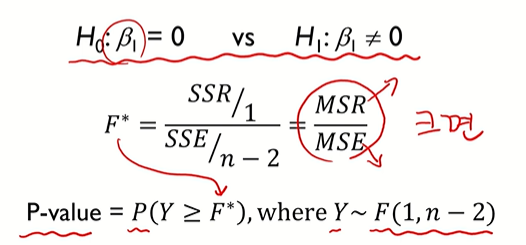
● 분산분석의 최종 목적 = 가설 검정에 사용할 것(기울기가 0일지 아닐지)
● 기울기가 중요 Why? 기울기가 0이라면 X가 Y에 아무런 영향을 미치지 못하는 것이기 때문


'AI > 김성범교수님 강의' 카테고리의 다른 글
| [핵심 머신러닝] 예측 모델링 (0) | 2025.01.21 |
|---|