Hands-On Machine Learning 정리 - 딥러닝(Chapter 10: 케라스를 사용한 인공 신경망 소개)
해당 부분부터는 책 기준으로 Part 2 신경망과 딥러닝 부분을 정리할 예정입니다.
10장에서의 내용은 책의 목차를 재구성하여 소개하고 다층 퍼셉트론(MLP;Multi-Layer Perceptron), Keras API를 사용한 인공 신경망 구현 등에 대하여 학습할 것입니다.
Chap 10.
- 퍼셉트론
- 시퀀셜 API를 사용해 회귀용 다층 퍼셉트론 만들기
- 은닉층 개수
1. 퍼셉트론(Perceptron)
1-1 퍼셉트론
○ 가장 간단한 인공 신경망 구조 중 하나
○ TLU(Threshold Logic Unit), LTU(Linear Threshold Unit)라고 불리는 조금 다른 형태의 인공 뉴런을 기반
○ 입/출력이 어떤 숫자 & 각각의 입력 연결은 가중치와 연관
○ TLU: 입력의 가중치 합을 계산 → 계산된 합에 계단 함수를 적용 → 결과 출력
$$ \textup{※} z=w_{1}x_{1} + w_{2}x_{2} + ... + w_{n}x_{n} = x^{T}w \textup{한뒤} $$
$$ ∴ h_{w}(x) = \textup{step}(z) \textup{... 여기에서} z = x^{T}w $$
○ 헤비사이드 계단 함수(Heaviside Step Function): 가장 널리 사용되는 계단함수
● 부호 함수(sign function)을 대신 사용하기도 함
[퍼셉트론에서 일반적으로 사용하는 계단 함수(임곗값을 0으로 가정)]
$$ \textup{heaviside}(z) = \begin{cases}0 & \textup{when} z<0 \\1 & \textup{when} z\geq0 \end{cases} $$
$$ \textup{sgn}(z) = \begin{cases}-1 & \text{when} z<0\\0 & \text{when} z=0\\+1 & \text{when}z>0 \end{cases} $$
○ 하나의 TLU는 간단한 선형 이진 분류 문제에 사용 가능
● 입력의 선형 조합을 계산 → IF 결과 > 임곗값 Then 양성 클래스 출력 else 음성 클래스 출력
(Like 로지스틱 회귀 or 선형 SVM 분류기)
○ 퍼셉트론은 층이 하나뿐인 TLU로 구성
● 각 TLU는 모든 입력에 연결되어 있음
● 완전 연결층(Fully Connected Layer): 한 층에 있는 모든 뉴런이 이전 층의 모든 뉴런과 연결되어 있는 상태
● 입력 뉴런: 퍼셉트론의 입력으로 특별한 통과 뉴런에 주입
- 어떤 입력이 주입되든 그냥 출력으로 통과시킴
- 입력층은 모두 입력뉴런으로 구성됨(보통 거기에 편향 특성이 더해짐)
● 편향 특성: 항상 1을 출력하는 특별한 종류의 뉴런인 편향 뉴런으로 표현
○ 입력 두 개와 출력 세 개로 구성된 퍼셉트론
● 샘플을 세 개의 다른 이진 클래스로 동시에 분류할 수 있으므로 다중 출력 분류기

○ 선형 대수학으로 아래 식을 사용해 한 번에 여러 샘플에 대해 인공 뉴런 층의 출력 계산 가능
● X: 입력 특성의 행렬
- 행: 샘플
- 열: 특성
● W: 가중치 행렬, 편향 뉴런을 제외한 모든 연결 가중치를 포함
- 행: 입력 뉴런
- 열: 출력층에 있는 인공 뉴런
● b: 편향 벡터, 편향 뉴런과 인공 뉴런 사이의 모든 연결 가중치를 포함(인공 뉴런마다 하나의 편향값 존재)
● Φ: 활성화 함수, 인공 뉴런이 TLU일 경우 이 함수는 계단 함수
※ 입력 뉴런 = 입력 자체 So, 입력 특성 개수 = 입력 뉴런의 개수 So, 행렬 X의 열 개수 = 행렬 W의 열 개수
[완전 연결 층의 출력 계산]
$$h_{w,b}(X) = \phi (XW+b) $$
※ 퍼셉트론을 하나의 TLU를 가진 작은 네트워크를 의미하는 용도로도 사용
※ 편향 뉴런은 신경망 그림에서 편의상 표시하지 않는 경우가 多
○ 퍼셉트론 훈련방법
● 두 뉴런이 동시에 활성화될 때마다 이들 사이의 연결 가중치가 증가하는 경향 → 헤브 학습(Hebbian Learning)
● 네트워크가 예측할 때 만드는 오차를 반영하도록 조금 변형된 규칙을 사용해 훈련
● 퍼셉트론 학습 규칙: 오차가 감소되도록 연결을 강화
● (구체적) 퍼셉트론에 한 번에 한 개의 샘플이 주입되면 각 샘플에 대해 예측이 생성
→ 잘못된 예측을 하는 모든 출력 뉴런에 대해 입력에 연결된 가중치 강화(올바른 예측을 만들 수 있도록 하기 위함)
● 각 출력 뉴런의 결정 경계는 선형 → 퍼셉트론도(Like 로지스틱 회귀 분류기) 복잡한 패턴 학습 불가
● 퍼셉트론 수렴 이론: 선형적으로 구분될 수 있다면 이 알고리즘이 정답에 수렴(로젠블라트가 증명)
● 사이킷런 : 하나의 TLU 네트워크를 구현한 Perceptron 클래스 제공(MLPClassifier, MLPRegressor도 제공)
※ 이 답이 고유한 것은 아니고 데이터가 선형적으로 구분된다면 가능한 초평면은 무한히 많음
[퍼셉트론 학습 규칙(가중치 업데이트)]
$$ w_{i, j}^{\textup{next step}} = w_{i,j} + \eta(y_{j} - \hat{y}_{j})x_{i} $$
$$ w_{i, j} = {\textup{i번째 입력 뉴런과 j번째 출력 뉴런 사이를 연결하는 가중치}} $$
$$ x_{i} = {\textup{현재 훈련 샘플의 i번째 뉴런의 입력값}} $$
$$ \hat{y}_{j} = {\textup{ 현재 훈련 샘플의 j번째 출력뉴런의 출력값 }} $$
$$ y_{j} = {\textup{현재 훈련 샘플의 j번째 출력뉴런의 타깃값 }} $$
$$ \eta = {\textup{학습률}} $$
[Perceptron클래스 사용 코드]
● 데이터셋: 붓꽃 데이터셋
● 퍼셉트론 학습알고리즘이 SGB(Stochastic Gradient Descent)과 유사
● 퍼셉트론은 클래스 확률을 제공하지 않으며 고정된 임곗값을 기준으로 예측 생성 So, 로지스틱 회귀가 선호됨
import numpy as np
from sklearn.datasets import load_iris
from sklearn.linear_model import Perceptron
iris = load_iris()
X = iris.data[:, (2, 3)] # 꽃잎 길이, 꽃잎 너비
y = (iris.target == 0).astype(np.int)
per_clf = Perceptron(max_iter=1000, tol=1e-3, random_state=42)
per_clf.fit(X, y)
y_pred = per_clf.predict([[2, 0.5]])
y_pred # array([1])1-2 다층 퍼셉트론과 역전파
○ 퍼셉트론을 여러 개 쌓아올리면 일부 제약을 줄일 수 있다 → 다층 퍼셉트론(MLP)
○ MLP는 XOR 문제를 풀 수 있음
● 입력: (0,0) | (1, 1) 일 때 0 출력
● 입력: (0,1) | (1, 0) 일때 1 출력
● 그림의 4개의 빨간 색 연결을 제외하고 다른 모든 연결의 가중치 = 1

○ (통과) 입력층 하나와 하나 이상의 은닉층(TLU 층)과 출력층으로 구성
○ 출력층을 제외하고 모든 층은 편향 뉴런을 포함하며 다음 층과 완전 연결되어 있음
○ 심층 신경망(DNN; Deep Neural Network) 은닉층을 여러 개 쌓아 올린 인공 신경망
※ 신호는 한 방향으로 만 흐름 So, 피드포워드 신경망(FNN;feedforward neural network)에 속함

1-2-2 역전파(Backpropagation)
○ 그레디언트를 자동으로 계산하는 경사 하강법
● 네트워크를 두 번(정방향 한 번, 역방향 한 번) 통과하는 것만으로
이 역전파 알고리즘은 모든 모델 파라미터에 대한 네트워크 오차의 그레디언트 계산 가능
→ 그레디언트 계산 후 평범한 경사하강법 수행(어떤 해결책으로 수렴될 때까지 반복)
● 오차를 감소시키기 위해 각 연결 가중치와 편향값이 어떻게 바뀌어야 할지 알 수 있음
자동 미분(Automatic Differentiation, Autodiff)
○ 자동으로 그레디언트를 계산하는 것
○ In 역전파: 후진 모드 자동 미분 (Reverse-Mode Autodiff)
● 빠르고 정확하며 미분할 함수가 변수(연결 가중치 등)가 많고 출력(손실 하나)이 적은 경우 적절
○ 알고리즘 상세히 보기
● 하나의 미니배치씩 진행하여 전체 훈련 세트를 처리(이 과정 반복, 각 반복 = 에포크)
● 정방향 계산(Forward Pass)
각 미니배치는 네트워크의 입력층으로 전달되어 첫 번째 은닉층으로 보내짐
→ 해당 층에 있는 모든 뉴런의 출력 계산 → 다음 층으로 결과를 전달
→ 다시 이 층의 출력 계산 & 결과를 다음 층으로 → 마지막 층(출력층)의 출력을 계산할 때까지 계속
※ 역방향 계산을 위해 중간 계산값을 모두 저장하는 것 외에는 예측을 만드는 것과 정확히 동일
● 그 다음 알고리즘이 네트워크 출력 오차 측정
(즉, 손실 함수를 사용해 기대 출력과 네트워크 실제 출력을 비교하고 오차 측정값 반환)
● 각 출력 연결이 오차에 기여하는 정도 계산(연쇄 법칙을 적용해 빠르고 정확하게 수행 가능)
● 다시 연쇄법칙을 적용해 이전 층의 연결 가중치가 이 오차의 기여정도에 얼마나 기여했는지 측정
(입력층에 도달할 때까지 역방향으로 계속됨)
● 이러한 역방향 단계는 오차 그레디언트를 거꾸로 전파함
So, 효율적으로 네트워크에 있는 모든 연결 가중치에 대한 오차 그레디언트 측정
○ 과정 요약
● 훈련 샘플에 대해 예측 생성(정방향 계산) + 오차 측정
● 역방향으로 각 층을 거치며 각 연결이 오차에 기여한 정도 측정(역방향 계산)
● 오차가 감소하도록 가중치 조정(경사 하강법 단계)
○ 다층 퍼셉트론 구조에 변화
● 계단 함수를 로지스틱(시그모이드)함수로 변환
● 이유: 계단 함수에는 수평선밖에 없음 So, 계산할 그레디어언트가 없음
But, 로지스틱은 어디서든 0이 아닌 그레디언트가 잘 정의되어 있기 때문
● 역전파 알고리즘은 로지스틱 함수뿐만 아니라 다른 활성화 함수와도 사용 가능
- 하이퍼볼릭 탄젠트 함수
: S자 모양, 연속적, 미분 가능
But 출력 범위가 -1 ~ 1 So, 훈련 초기에 각 층의 출력을 원점 근처로 모으는 경향이 있음
- ReLU함수
: 연속적, But z= 1에서 미분 불가
※ ReLU함수의 값이 0보다 클 때 기울기가 항상 1, So 오차그레디언트를 그래도 역전파시킴
원점에서 기울기가 정의되지 않지만 일반적으로 0을 사용
So, ReLU함숫값이 0보다 작거나 같을 때는 오차그레디언트를 역전파하지 않음

● 활성화 함수가 필요한 이유
- 선형 변환을 여러 개 연결해도 얻을 수 있는 것은 선형 변환뿐
- 따라서 층 사이에 비선형성을 추가하지 않으면 아무리 층을 많이 쌓아도 하나의 층과 동일해짐
- 반대로 비선형 활성화 함수가 있는 충분히 큰 심층 신경망은 이론적으로 어떤 연속 함수도 근사할 수 있음
[시그모이드 함수]
$$ \sigma(z)=\frac{1}{(1+\textup{exp}(-z))} $$
[하이퍼볼릭 탄젠트 함수(쌍곡 탄젠트 함수)]
$$ \textup{tanh}(z) = 2\sigma (2z) - 1 $$
[ReLU 함수]
$$ \textup{ReLU}(z) = \textup{max}(0,z) $$
[시각화 코드]
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def relu(z):
return np.maximum(0, z)
def derivative(f, z, eps=0.000001):
return (f(z + eps) - f(z - eps))/(2 * eps)z = np.linspace(-5, 5, 200)
plt.figure(figsize=(11,4))
plt.subplot(121)
plt.plot(z, np.sign(z), "r-", linewidth=1, label="Step")
plt.plot(z, sigmoid(z), "g--", linewidth=2, label="Sigmoid")
plt.plot(z, np.tanh(z), "b-", linewidth=2, label="Tanh")
plt.plot(z, relu(z), "m-.", linewidth=2, label="ReLU")
plt.grid(True)
plt.legend(loc="center right", fontsize=14)
plt.title("Activation functions", fontsize=14)
plt.axis([-5, 5, -1.2, 1.2])
plt.subplot(122)
plt.plot(z, derivative(np.sign, z), "r-", linewidth=1, label="Step")
plt.plot(0, 0, "ro", markersize=5)
plt.plot(0, 0, "rx", markersize=10)
plt.plot(z, derivative(sigmoid, z), "g--", linewidth=2, label="Sigmoid")
plt.plot(z, derivative(np.tanh, z), "b-", linewidth=2, label="Tanh")
plt.plot(z, derivative(relu, z), "m-.", linewidth=2, label="ReLU")
plt.grid(True)
#plt.legend(loc="center right", fontsize=14)
plt.title("Derivatives", fontsize=14)
plt.axis([-5, 5, -0.2, 1.2])
plt.show()1-3 회귀를 위한 다층 퍼셉트론
○ 회귀작업에서 값 하나를 출력하는 데 하나의 출력 뉴런이 필요 → 출력 뉴런의 출력: 예측된 값
○ 다변량 회귀(Multivariate Regression): (동시에 여러 값을 예측하는 경우) 출력 차원마다 출력 뉴런이 하나씩 필요
○ 일반적으로 회귀용 다층 퍼셉트론 만들 때 출력 뉴런에 활성화 함수를 사용하지 않고 어떤 범위의 값도 출력되도록 함
● IF 출력이 항상 양수여야 한다면? 출력층에 ReLU활성화 함수 or softplus 활성화 함수 사용 가능
● IF 어떤 범위 안의 값을 예측하고 싶다?
로지스틱 함수 or 하이퍼볼릭 탄젠트 함수 사용 → 레이블의 스케일을 적절한 범위로 조정 가능
● 훈련에 사용하는 손실함수(전형적으로): MSE(평균 제곱 오차)
But, IF 훈련 세트에 이상치 多 → 평균 절댓값 오차(MAE) | 후버 손실 (MSE와 MAE를 조합한 손실)
후버 손실
○ 오차가 임곗값 δ (전형적으로 1)보다 작을 때 이차함수
○ 오차 > δ → 선형 함수
○ 선형 함수 부분은 MSE보다 이상치에 덜 민감
○ 이차 함수 부분은 MAE보다 더 빠르고 정확하게 수렴하도록 도와줌
[softplus 활성화 함수]
$$ softplus(z) = \textup{log} (1 + \textup{exp}(z)) $$
[회귀 MLP의 전형적인 구조]
| 하이퍼파라미터 | 일반적인 값 |
| 입력 뉴런 수 | 특성마다 하나(e.g. MNIST의 경우 28 * 28 = 784) |
| 은닉층 수 | 일반적으로 1 ~ 5 |
| 은닉층의 뉴런 수 | 일반적으로 10 ~ 100 |
| 출력 뉴런 수 | 예측 차원마다 하나 |
| 은닉층의 활성화 함수 | ReLU(or SELU) |
| 출력층의 활성화 함수 | - 없음 - 출력이 양수일 때: ReLU | softplus | c - 출력을 특정 범위로 제한할 때: losigtic/tanh |
| 손실 함수 | MSE or IF 이상치 존재 then MAE/Huber |
1-4 분류를 위한 다층 퍼셉트론
○ 이진 분류 문제에서는 로지스틱 활성화 함수를 가진 하나의 출력 뉴런만 필요(출력 범위: 0 ~ 1 사이 실수)
○ 다중 퍼셉트론은 다중 레이블 이진 분류 문제를 쉽게 처리 가능
e.g. 이메일 스팸 메일인지 아닌지 예측하고 동시에 긴급한 메일인지 아닌지 예측하는 분류 시스템
● 로지스틱 활성화 함수를 가진 두 출력 뉴런이 필요
- 첫 번째 뉴런: 이메일이 스팸일 확률 출력
- 두 번째 뉴런: 긴급한 메일일 확률 출력
e.g. 각 샘플이 3개 이상의 클래스 中 한 클래스에만 속할 수 있다면?(숫자 이미지 분류에서 0 ~ 9)
- 클래스마다 하나의 출력 뉴런이 필요
- 출력층에는 소프트맥스 활성화 함수 사용해야 함
※ 소프트맥스 함수: 모든 예측 확률을 0 ~ 1 사이로 만들고 더했을 때 1이 되도록
※ 클래스가 서로서로 배타적일 경우 필요
※ 소프트맥스 함수 공식: 분모는 모든 클래스의 출력에 지수 함수를 적용해 더한 값
=> 다중분류(Multiclass Classification)
○ 확률 분포를 예측해야 하므로 손실 함수에는 크로스 엔트로피 손실(로그 손실)[4장]을 선택하는 것이 좋음
[분류 MLP의 전형적인 구조]
| 하이퍼파라미터 | 이진 분류 | 다중 레이블 분류 | 다중 분류 |
| 입력층과 은닉층 | 회귀와 동일 | ||
| 출력 뉴런 수 | 1개 | 레이블마다 1개 | 클래스마다 1개 |
| 출력층의 활성화 함수 | 로지스틱 함수 | 소프트맥스 함수 | |
| 손실 함수 | 크로스 엔트로피 | ||

2. 케라스로 다층 퍼셉트론 구현하기
2-1 시퀀셜 API를 사용해 이미지 분류기 만들기
○ 데이터셋: 패션 MNIST
○ 데이터 형태: 10개 클래스로 이루어진 28*28 픽셀 크기의 흑백 이미지 70,000개
2-1-1 케라스를 사용해 데이터 적재
○ 데이터 적재 시 중요한 차이점
● 각 이미지가 784 크기의 1D 배열이 아닌 28*28 크기의 배열
● 픽셀 강도가 실수가 아닌 정수(0 ~ 255)
○ 훈련 세트와 테스트 세트로 나눠져 있지만 검증 세트 없으므로 만들어줌
○ 경사 하강법으로 신경망을 훈련하기에 입력 특성의 스케일 조정(0 ~ 1 범위로)
○ 패션 MNIST는 레이블에 해당하는 아이템을 나타내기 위해 클래스 이름의 리스트 생성

import tensorflow as tf
from tensorflow import keras
fashion_mnist = keras.datasets.fashion_mnist
(X_train_full, y_train_full), (X_test, y_test) = fashion_mnist.load_data()
X_train_full.shape # (60000, 28, 28)
X_train_full.dtype # dtype('uint8')
- 검증 세트 생성 및 스케일 조정
X_valid, X_train = X_train_full[:5000] / 255., X_train_full[5000:] / 255.
y_valid, y_train = y_train_full[:5000], y_train_full[5000:]
X_test = X_test / 255.
- 클래스 이름의 리스트 생성
class_names = ["T-shirt/top", "Trouser", "Pullover", "Dress", "Coat",
"Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot"]
- 데이터셋 시각화
n_rows = 4
n_cols = 10
plt.figure(figsize=(n_cols * 1.2, n_rows * 1.2))
for row in range(n_rows):
for col in range(n_cols):
index = n_cols * row + col
plt.subplot(n_rows, n_cols, index + 1)
plt.imshow(X_train[index], cmap="binary", interpolation="nearest")
plt.axis('off')
plt.title(class_names[y_train[index]], fontsize=12)
plt.subplots_adjust(wspace=0.2, hspace=0.5)
plt.show()2-2 시퀀셜 API를 사용해 회귀용 다층 퍼셉트론 만들기
○ 신경망 생성
● 두 개의 은닉층으로 이루어진 분류용 다층 퍼셉트론
○ 모델에 있는 모든 층을 출력(summary() 메서드)
● 각 층의 이름(지정하지 않으면 자동 생성)
● 출력 크기 & 파라미터 개수
- 마지막에 훈련되는 파라미터, 훈련되지 않은 파라미터를 포함해 전체 파라미터 개수 출력
○ Dense 층은 대칭성을 깨뜨리기 위해 연결 가중치를 무작위로 초기화(편향 = 0)
가중치 행렬의 크기는 입력의 크기에 달려있음
So, Sequential 모델에 첫 번째 층을 추가할 때, input_shape 매개변수를 지정한 것
But 입력 크기를 지정하지 않아도 케라스는 모델을 빌드하기 전까지 입력 크기를 기다림
※ 모델 빌드는 실제 데이터를 주입할 때나 build() 메서드를 호출할 때 발생
※ 모델이 실제 빌드되기 전에 층이 가중치를 가지지 않으면 특정 작업 수행이 불가
So, 모델 만들 때 입력 크기를 알고 있다면 지정하는 것이 좋음
○ 모델 컴파일(complie() 메서드 호출)
● 사용할 손실 함수와 옵티마이저를 지정 → 훈련과 평가 시에 계산할 지표를 추가 지정 가능
loss="sparse_categorical_crossentropy"를 사용하는 것 = loss=keras.losses.sparse_categorical_crossentropy
○ 비슷하게
● optimizer="sgd" = optimizer=keras.optimizers.SGD()
● metrices=["accuracy"] = metrics=[keras.metrics.sparse_categorical_accuracy]
○ 모델 훈련과 평가(fit() 메서드 호출)
● History 객체:
- 훈련 파라미터(history.params)
- 수행된 에포크 리스트(history.epoch)
- 에포크 끝날 때마다 훈련 세트와(있는 경우) 검증 세트에 대한 손실 & 측정한 지표를 담은 딕셔너리(history.history)
※ 훈련 곡선을 볼 때 왼쪽으로 에포크의 절반만큼 이동해서 생각하기

○ 모델을 사용해 예측 만들기(predict() 메서드 사용)
[코드]
- 신경망 생성
● Sequential 모델 생성: 순서대로 연결된 층을 일렬로 쌓아서 구성(= 시퀀셜 API)
● 첫 번째 층 만들고 모델에 추가. Flatten 층 = 입력 이미지를 1D 배열로 변환
즉, 입력 데이터 X 받음 → X.reshape(-1, 1)를 계산
● 뉴런 300개를 가진 Dense 은닉층을 추가 ← ReLU 활성화 함수를 사용
Dense 층마다 각자 가중치 행렬을 관리
층의 뉴런과 입력 사이의 모든 연결 가중치가 포함(편향도 벡터로 관리)
● 뉴런 100개를 가진 두 번째 Dense 은닉층을 추가(ReLU함수 사용)
● 뉴런 10개를 가진 Dense 출력층을 추가(배타적 클래스이므로) 소프트맥스 활성화 함수 사용
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28, 28]))
model.add(keras.layers.Dense(300, activation="relu"))
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
- 층을 하나씩 추가하지 않고 Sequential 모델을 만들 때 층의 리스트 전달 가능
keras.backend.clear_session()
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(300, activation="relu"),
keras.layers.Dense(100, activation="relu"),
keras.layers.Dense(10, activation="softmax")
])
- 모델 요약 출력
● Dense 층은 보통 많은 파라미터를 가짐
● 훈련 데이터를 학습하기 충분한 유연성을 지님 + 과대적합의 위험을 가진다
model.summary()
- 모델에 있는 층의 리스트를 출력하거나 인덱스로 층을 쉽게 선택 가능
hidden1 = model.layers[1]
hidden1.name # 'dense'
model.get_layer(hidden1.name) is hidden1 # True
# 연결 가중치와 편향 출력
weights, biases = hidden1.get_weights()
weights
weights.shape
biases
- 모델 compile()
● 레이블: 정수 하나로 구성(샘플마다 타깃 클래스 인덱스 하나 존재 0 ~ 9까지 정수)
● 클래스: 배타적 So, "sparse_categorical_crossentropy" 손실 사용
● 옵티마이저: "sgd" 사용 → 기본 SGD 사용해 모델 훈련
(= 역전파 알고리즘 수행 = 후진 모드 자동 미분과 경사하강법)
※ IF 샘플마다 클래스별 타깃 확률 보유(e.g. 원-핫 벡터) "categorical_crossentropy" 손실 사용
※ IF 이진 분류 사용 "softmax" → "sigmoid" 함수 & "binary_corssentropy" 사용
model.compile(loss="sparse_categorical_crossentropy",
optimizer="sgd",
metrics=["accuracy"])
- 모델 훈련 & 학습 곡선 시각화
history = model.fit(X_train, y_train, epochs=30,
validation_data=(X_valid, y_valid))
history.params # {'epochs': 30, 'steps': 1719, 'verbose': 1}
print(history.epoch)
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]
history.history.keys() # dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])import pandas as pd
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
save_fig("keras_learning_curves_plot")
plt.show()
- 모델 사용해 예측
● 실제로 새로운 샘플이 없기 때문에 테스트 세트의 처음 3개 샘플을 사용
X_new = X_test[:3]
y_proba = model.predict(X_new)
y_proba.round(2)2-2 시퀀셜 API를 사용해 회귀용 다층 퍼셉트론 만들기
○ 데이터셋: 캘리포니아 주택 가격 데이터셋
● fetch_california_housing() 함수로 데이터 적재
- 특징: 수치 특성만 존재(ocean_proximity 특성 X) & 누락 데이터 X
○ 시퀀셜 API를 사용해 회귀용 MLP 구축/훈련/평가/예측 방법은 분류와 유사
○ 주된 차이점:
● 출력층이 활성화 함수가 없는 하나의 뉴런(∵ 하나의 값을 예측)
● 손실함수로 평균 제곱오차(MSE)를 사용
● 이 데이터셋에 잡음이 많음 So, 과대적합을 막는 용도로 뉴런 수가 적은 은닉층 하나만 사용
[코드]
- 데이터 적재 & 데이터 분할 및 특성 스케일 조정
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
housing = fetch_california_housing()
X_train_full, X_test, y_train_full, y_test = train_test_split(housing.data, housing.target, random_state=42)
X_train, X_valid, y_train, y_valid = train_test_split(X_train_full, y_train_full, random_state=42)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_valid = scaler.transform(X_valid)
X_test = scaler.transform(X_test)
- 모델 구축
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=X_train.shape[1:]),
keras.layers.Dense(1)
])
model.compile(loss="mean_squared_error", optimizer=keras.optimizers.SGD(learning_rate=1e-3))
history = model.fit(X_train, y_train, epochs=20, validation_data=(X_valid, y_valid))
mse_test = model.evaluate(X_test, y_test)
X_new = X_test[:3] # 새로운 샘플이라고 생각
y_pred = model.predict(X_new)2-3 함수형 API를 사용해 복잡한 모델 만들기
○ 순차적이지 않은 신경망 예: 와이드 & 딥 신경망(Wide & Deep)
○ 와이드 & 딥 신경망
● 아래 그림과 같이 입력의 일부 또는 전체가 출력층에 바로 연결
● 신경망이 (깊게 쌓은 층을 사용한) 복잡한 패턴과 (짧은 경로를 사용한) 간단한 규칙 모두 학습 가능
○ 이와는 대조적으로 일반적인 MLP는 네트워크에 있는 층 전체에 모든 데이터 통과시킴
→ 데이터에 있는 간단한 패턴이 연속된 변환으로 인해 왜곡될 수 있음
○ 이후는 동일

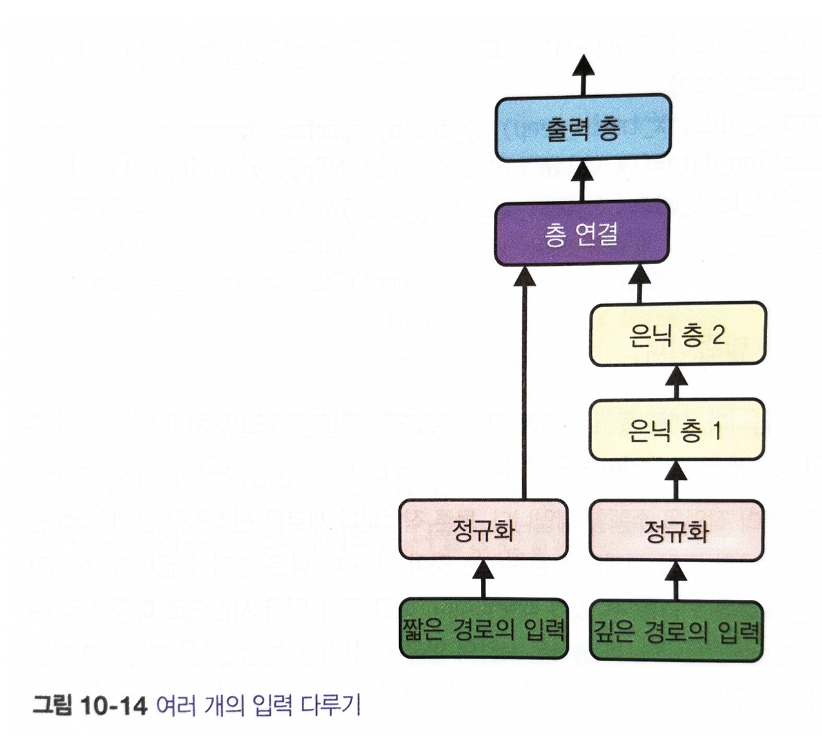
○ 여러 개의 입력을 다루기
○ 여러 개의 출력이 필요한 경우
● 그림에 있는 주요 물체를 분류하고 위치를 알아야 하는 경우(회귀&분류를 함께 사용하는 경우)
● 동일한 데이터에서 독립적인 여러 작업을 수행하는 경우(얼굴 사진으로 다중 작업 분류)
● 규제 기법으로 사용하는 경우(신경망 구조 안에 보조 출력을 추가 가능)
○ 보조 출력을 추가하는 방법
● 적절한 층에 연결하고 모델의 출력 리스트에 추가
● 각 출력은 자신만의 손실 함수가 필요 So, 모델을 컴파일할 때 손실의 리스트를 전달해야 함
※ 하나의 손실을 전달하면 케라스는 모든 출력의 손실함수가 동일하다고 가정
● 보조 출력보다 주 출력에 더 관심이 많다면?(∵ 보조 출력은 규제로만 사용됨) 주출력의 손실에 더 많은 가중치를 부여
※ 모델 컴파일 시 손실 가중치를 지정 가능
[코드]
- 함수형 API를 사용해 신경망 생성
● Input 객체 생성: shape와 dtype 포함해 모델 입력 정의 → 한 모델은 여러 개의 입력 보유 가능
● 30개의 뉴런과 ReLU 활성화 함수를 가진 Dense 층 생성
→ 이 층은 만들어지자마자 입력과 함께 함수처럼 호출(So, 함수형 API라 명명)
→ 케라스에 층이 연결될 방법을 알려주었을 뿐 아직 어떤 데이터도 처리 X
● 두 번째 은닉층 생성 → 함수처럼 호출 → 이는 첫 번째 층의 출력을 전달함
● Concatenate 층 생성 → 함수처럼 호출 → 두 번째 은닉층의 출력과 입력을 연결 → Concatenate 층 생성
→ 주어진 입력으로 바로 호출
※ keras.layers.concatenate() 함수를 사용도 가능
● 하나의 런 과 활성화 함수가 없는 출력층 생성 → Concatenate 층이 만든 결과를 사용해 호출
● 사용할 입력과 출력을 지정해 keras Model 생성
※ IF 일부 특성은 짧은 경로로 전달하고 다른 특성들은 깊은 경로를 사용하고 싶다면?
→ 여러 입력을 사용
np.random.seed(42)
tf.random.set_seed(42)
input_ = keras.layers.Input(shape=X_train.shape[1:])
hidden1 = keras.layers.Dense(30, activation="relu")(input_)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.concatenate([input_, hidden2])
output = keras.layers.Dense(1)(concat)
model = keras.models.Model(inputs=[input_], outputs=[output])
model.summary()
- 여러 입력을 사용하는 방법
np.random.seed(42)
tf.random.set_seed(42)
input_A = keras.layers.Input(shape=[5], name="wide_input")
input_B = keras.layers.Input(shape=[6], name="deep_input")
hidden1 = keras.layers.Dense(30, activation="relu")(input_B)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
output = keras.layers.Dense(1, name="main_output")(concat)
aux_output = keras.layers.Dense(1, name="aux_output")(hidden2)
model = keras.models.Model(inputs=[input_A, input_B], outputs=[output, aux_output])model.compile(loss=["mse", "mse"], loss_weights=[0.9, 0.1], optimizer=keras.optimizers.SGD(learning_rate=1e-3))
history = model.fit([X_train_A, X_train_B], [y_train, y_train], epochs=20,
validation_data=([X_valid_A, X_valid_B], [y_valid, y_valid]))
total_loss, main_loss, aux_loss = model.evaluate(
[X_test_A, X_test_B], [y_test, y_test])
y_pred_main, y_pred_aux = model.predict([X_new_A, X_new_B])2-4 서브클래싱 API로 동적 모델 만들기
○ 시퀀셜 API와 함수형 API는 모두 선언적(declarative) So, 사용할 층과 연결 방식을 먼저 정의해야 함
● 장점
- 모델을 저장, 복사, 공유가 편리
- 모델 구조를 출력 | 분석이 편리
- 모델에 데이터가 주입되기 전에 크기 짐작, 타입 확인으로 에러를 일찍 발견 가능
- 전체 모델이 층으로 구성된 정적그래프 So, 디버깅도 편하지만 정적이라는 것이 단점이 되기도 함
○ 여러 가지 동적인 구조가 필요한 경우(≒ 명령형 프로그래밍 스타일이 필요하다) → 서브 클래싱 API가 정답
○ 유연성이 높아지면 그에 따른 비용이 발생
● 모델 구조가 call() 메서드 안에 숨겨져 있기에 케라스가 이를 쉽게 분석할 수 없음(= 모델 저장 복사 불가)
● summary() 메서드를 호출하면 층의 목록만 나열되고 층 간의 연결 정보를 얻을 수 없음
● 케라스가 타입, 크기를 미리 확인 불가하여 실수가 발생하기 쉬움
[코드]
○ 코드 설명
● 함수형 API와 매우 비슷 But Input 클래스의 객체를 만들 필요가 없음
● 대신 call() 메서드의 input 매개변수를 사용
● 생성자에 있는 층 구성과 call() 메서드에 있는 정방향 계산을 분리함
● 차이점: call() 메서드 안에서 원하는 어떤 계산도 사용 가능(for/if/텐서플로 저수준 연산 등)
class WideAndDeepModel(keras.models.Model):
def __init__(self, units=30, activation="relu", **kwargs):
super().__init__(**kwargs)
self.hidden1 = keras.layers.Dense(units, activation=activation)
self.hidden2 = keras.layers.Dense(units, activation=activation)
self.main_output = keras.layers.Dense(1)
self.aux_output = keras.layers.Dense(1)
def call(self, inputs):
input_A, input_B = inputs
hidden1 = self.hidden1(input_B)
hidden2 = self.hidden2(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
main_output = self.main_output(concat)
aux_output = self.aux_output(hidden2)
return main_output, aux_output
model = WideAndDeepModel(30, activation="relu")model.compile(loss="mse", loss_weights=[0.9, 0.1], optimizer=keras.optimizers.SGD(learning_rate=1e-3))
history = model.fit((X_train_A, X_train_B), (y_train, y_train), epochs=10,
validation_data=((X_valid_A, X_valid_B), (y_valid, y_valid)))
total_loss, main_loss, aux_loss = model.evaluate((X_test_A, X_test_B), (y_test, y_test))
y_pred_main, y_pred_aux = model.predict((X_new_A, X_new_B))2-5 모델 저장/복원/콜백
○ 케라스는 HDF5 포맷을 사용하여 모델 구조와 층의 모델 파라미터를 저장
(= 모든 층의 하이퍼파라미터, 연결 가중치와 편향, 옵티마이저)
시퀀셜, 함수형 API에서는 이 방법을 사용 가능하지만 모델 서브클래싱에서는 사용 불가
○ save_weights()와 load_weights() 메서드를 사용해 모델 파라미터를 저장 & 복원 가능
● 그 외에는 모두 수동으로 저장하고 복원해야 함
○ 서브클래싱 API를 사용한 모델을 저장하는 대안: pickle 모듈을 사용해 모델 객체 직렬화
2-5-1 콜백
○ fit() 메서드의 callbacks 매개변수를 사용해 케라스가 훈련의 시작 | 끝에 호출할 객체 리스트 지정 가능
[코드]
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=[8]),
keras.layers.Dense(30, activation="relu"),
keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer=keras.optimizers.SGD(learning_rate=1e-3))
history = model.fit(X_train, y_train, epochs=10, validation_data=(X_valid, y_valid))
mse_test = model.evaluate(X_test, y_test)- 저장
model.save("my_keras_model.h5")- 모델 로드
model = keras.models.load_model("my_keras_model.h5")
model = keras.models.load_model("my_keras_model.h5")
model.save_weights("my_keras_weights.ckpt")
model.load_weights("my_keras_weights.ckpt")- 콜백
keras.backend.clear_session()
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=[8]),
keras.layers.Dense(30, activation="relu"),
keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer=keras.optimizers.SGD(learning_rate=1e-3))
# 콜백
checkpoint_cb = keras.callbacks.ModelCheckpoint("my_keras_model.h5", save_best_only=True)
history = model.fit(X_train, y_train, epochs=10,
validation_data=(X_valid, y_valid),
callbacks=[checkpoint_cb])
model = keras.models.load_model("my_keras_model.h5") # 최상의 모델로 롤백
mse_test = model.evaluate(X_test, y_test)- 조기 종료 구현
● 다른 방법: EarlyStopping 콜백 사용
: 일정 에포크동안 검증 세트에 대한 점수가 향상되지 않으면 훈련을 멈춤
EarlyStopping 콜백이 훈련이 끝난 후 최상의 가중치를 복원 So, 저장된 모델을 따로 복원할 필요 X
model.compile(loss="mse", optimizer=keras.optimizers.SGD(learning_rate=1e-3))
early_stopping_cb = keras.callbacks.EarlyStopping(patience=10,
restore_best_weights=True)
history = model.fit(X_train, y_train, epochs=100,
validation_data=(X_valid, y_valid),
callbacks=[checkpoint_cb, early_stopping_cb])
mse_test = model.evaluate(X_test, y_test)- 더 많은 제어를 원하면? 사용자 정의 콜백 생성
class PrintValTrainRatioCallback(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
print("\nval/train: {:.2f}".format(logs["val_loss"] / logs["loss"]))val_train_ratio_cb = PrintValTrainRatioCallback()
history = model.fit(X_train, y_train, epochs=1,
validation_data=(X_valid, y_valid),
callbacks=[val_train_ratio_cb])2-6 텐서보드를 사용해 시각화
○ 텐서보드를 사용하려면 프로그램을 수정하여 이벤트 파일(이진 로그 파일)에 시각화하려는 데이터를 출력해야 함
● Summary:각각의 이진 데이터 레코드
○ 아래 코드 방법
● 루트 로그 디렉터리 정의: 텐서보드 로그를 위해 사용
● 함수
- 현재 날짜와 시간을 사용해 실행할 때마다 다른 서브디렉터리 경로를 생성
[코드]
import os
root_logdir = os.path.join(os.curdir, "my_logs")
def get_run_logdir():
import time
run_id = time.strftime("run_%Y_%m_%d-%H_%M_%S")
return os.path.join(root_logdir, run_id)
run_logdir = get_run_logdir()
run_logdirkeras.backend.clear_session()
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=[8]),
keras.layers.Dense(30, activation="relu"),
keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer=keras.optimizers.SGD(learning_rate=1e-3))- 텐서보드 서버 시작
1. 터미널 명령 실행
● virtualenv안에서 텐서플로를 설치했다면 이 환경을 먼저 활성화
● 프로젝트 루트 디렉터리에서 아래 명령 실행
● 웹 브라우저를 열고 localhost:6006에 접속하여 텐서보드를 사용
● 사용이 끝나면 터미널에서 Ctrl-C를 눌러 텐서보드 서버를 종료
$ tensorboard --logdir=./my_logs --port=60062. 주피터 안에서 실행
● 텐서보드 확장 로드(1번째 줄 코드)
● 포트 6006에서 텐서보드 서버 실행 & 접속(2번째 줄 코드)
%load_ext tensorboard
%tensorboard --logdir=./my_logs --port=6006run_logdir2 = get_run_logdir()
keras.backend.clear_session()
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=[8]),
keras.layers.Dense(30, activation="relu"),
keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer=keras.optimizers.SGD(learning_rate=0.05))
tensorboard_cb = keras.callbacks.TensorBoard(run_logdir2)
history = model.fit(X_train, y_train, epochs=30,
validation_data=(X_valid, y_valid),
callbacks=[checkpoint_cb, tensorboard_cb])3. 신경망 하이퍼파라미터 튜닝하기
○ 신경망의 유연성은 장점이자 단점 why? 조정할 하이퍼파라미터가 많기 때문
○ 어떤 하이퍼파라미터 조합이 주어진 문제에 최적인지 아는 방법
● 많은 하이퍼파라미터 조합 시도 → 검증세트에서 확인
○ 하이퍼파라미터 최적화에 사용할 수 있는 파이썬 라이브러리
● Hyperopt
- 모든 종류의 복잡한 탐색 공간에 대해 최적화를 수행할 수 있는 라이브러리
● Hyperas, kopt, Talos
- 케라스 모델을 위한 하이퍼파라미터 최적화 라이프러리(처음 두 개는 Hyperopt 기반)
● Keras Tuner
- 사용하기 쉬운 케라스 하이퍼파라미터 최적화 라이브러리(구글 제작)
● Scikit-Optimize(skopt)
- 범용 최적화 라이브러리(BayesSearchCV클래스는 GridSearch와 비슷한 인터페이스를 사용해 베이즈 최적화)
● Spearmint: 베이즈 최적화 라이브러리
● Hyperband: 빠른 하이퍼파라미터
[코드]
- 일련의 하이퍼파라미터로 케라스 모델 생성 & 컴파일 함수 생성
● 은닉층/뉴런 개수로 단변량 회귀를 위한 간단한 Sequential 모델 생성
● 지정된 학습률을 사용하는 SGD 옵티마이저로 모델을 컴파일
keras.backend.clear_session()
np.random.seed(42)
tf.random.set_seed(42)
def build_model(n_hidden=1, n_neurons=30, learning_rate=3e-3, input_shape=[8]):
model = keras.models.Sequential()
model.add(keras.layers.InputLayer(input_shape=input_shape))
for layer in range(n_hidden):
model.add(keras.layers.Dense(n_neurons, activation="relu"))
model.add(keras.layers.Dense(1))
optimizer = keras.optimizers.SGD(learning_rate=learning_rate)
model.compile(loss="mse", optimizer=optimizer)
return model- build_model() 함수를 사용해 KerasRegressor 클래스의 객체 생성
● KerasRegressor 객체: build_model() 함수로 만들어진 케라스 모델을 감싸는 간단한 레퍼(wrapper)
● 사이킷런은 손실이 아니라 점수를 계산(높을수록 좋음) So, 출력 점수는 음수의 MSE
keras_reg = keras.wrappers.scikit_learn.KerasRegressor(build_model)
keras_reg.fit(X_train, y_train, epochs=100,
validation_data=(X_valid, y_valid),
callbacks=[keras.callbacks.EarlyStopping(patience=10)])- 은닉층/뉴런 개수, 학습률을 사용해 하이퍼파라미터 탐색 수행
● 랜덤탐색은 하드웨어와 데이터셋의 크기, 모델 복잡도, n_iter, cv 매개변수에 따라 시간이 오래 걸릴 수 있음
● 실행이 끝나면 랜덤 탐색이 찾은 최상의 하이퍼파라미터와 훈련된 케라스 모델을 얻을 수 있음
from scipy.stats import reciprocal
from sklearn.model_selection import RandomizedSearchCV
param_distribs = {
"n_hidden": [0, 1, 2, 3],
"n_neurons": np.arange(1, 100).tolist(),
"learning_rate": reciprocal(3e-4, 3e-2).rvs(1000).tolist(),
}
rnd_search_cv = RandomizedSearchCV(keras_reg, param_distribs, n_iter=10, cv=3, verbose=2)
rnd_search_cv.fit(X_train, y_train, epochs=100,
validation_data=(X_valid, y_valid),
callbacks=[keras.callbacks.EarlyStopping(patience=10)])rnd_search_cv.best_params_
rnd_search_cv.best_score_3-1 은닉층 개수
○ 복잡한 문제에서는 심층 신경망이 얕은 신경망보다 파라미터 효율성이 훨씬 좋음
○ 심층신경망은 복잡한 함수를 모델링하는 데 얕은 신경망보다 훨씬 적은 수의 뉴런을 사용
● So, 동일한 양의 훈련 데이터에서 더 높은 성능을 낼 수 있음
○ 계층 구조는 심층 신경망이 좋은 솔루션으로 빨리 수렴하게끔 도와주고 새로운 데이터에 일반화되는 능력도 향상시켜줌
3-2 은닉층의 뉴런 개수
○ 입력층과 출력층의 뉴런 개수는 해당 작업에 필요한 입출력의 형태에 따라 결정됨
● e.g. MNIST
- 입력 뉴런: 28*28=784개
- 출력 뉴런: 10개
○ 은닉층의 구성방식: 일반적으로 각 층의 뉴런을 점점 줄여서 깔때기처럼 구성
● why? 저수준의 많은 특성이 고수준의 적은 특성으로 합쳐질 수 있기 때문
● 요즘에는 대부분의 경우 모든 은닉층에 같은 크기를 사용해도 동일하거나 더 나은 성능을 냄
● 또한, 튜닝할 하이퍼파라미터가 층마다 한 개씩이 아니라 전체를 통틀어 한 개가 됨
● 데이터셋에 따라 다르지만 다른 은닉층보다 첫 번째 은닉층을 크게 하는 것이 도움이 됨
○ 층의 개수와 마찬가지로 네트워크가 과대적합이 되기 전까지 점진적으로 뉴런 수를 늘릴 수 있음
● 스트레치 팬츠(Stretch Pants)
- 필요한 것보다 더 많은 층과 뉴런을 가진 모델을 선택 → 과대적합되지 않도록 조기종료나 규제 기법 사용
※ 일반적으로 층의 뉴런 수보다 층 수를 늘리는 쪽이 이득이 많음
3-3 학습률, 배치 크기 그리고 다른 하이퍼파라미터
3-3-1 가장 중요한 하이퍼파라미터 중 일부와 조정하는 방법
○ 학습률
● 일반적으로 최적의 학습률 = 최대 학습률의 절반 정도
● 좋은 학습률을 찾는 방법
- 매우 낮은 학습률에서 점진적으로 매우 큰 학습률까지 수백 번 반복하여 모델을 훈련
- 반복마다 일정한 값을 학습률에 곱함
- 처음에 손실이 줄어들다가 학습률이 커지면서 손실이 다시 커짐
- 최적의 학습률: 손실이 다시 상승하는 지점보다 조금 아래
- 모델을 다시 초기화 후 최적의 학습률로 훈련
○ 배치 크기
● 모델 성능과 훈련 시간에 큰 영향을 미칠 수 있음
● 큰 배치 크기 사용 장점: GPU와 같은 하드웨어 가속기를 효율적으로 활용 가능
● So, 훈련 알고리즘이 초당 더 많은 샘플을 처리 가능
● 학습률 예열(작은 학습률로 훈련을 시장해서 점점 커지는 기법)을 사용해 큰 배치 크기 시도
- IF 훈련 불안정 | 최종 성능이 만족스럽지 못하다 THEN 작은 배치 크기 사용
○ 활성화 함수: 앞에서 설명했지만 일반적으로 ReLU 활성화 함수가 모든 은닉층에 좋은 기본값
● 출력층의 활성화함수는 수행하는 작업에 따라 달라짐
○ 반복 횟수: 대부분의 경우 훈련 반복 횟수는 튜닝할 필요가 없지만 조기 종료를 사용
※ 최적의 학습률은 다른 하이퍼파라미터에 의존적
※ 특히 배치 크기에 큰 영향을 받음 So, 하이퍼파라미터를 수정하면 반드시 학습률도 튜닝해야 함
다음 장에서는 매우 깊은 네트워크를 훈련하는 방법을 설명합니다.
[다음 장에 학습 내용]
- 텐서플로의 저수준 API를 사용해 모델을 커스터 마이징하는 방법
- 데이터 API를 사용해 효과적으로 데이터를 적재하고 전처리하는 방법
- 이미지 처리를 위한 합성곱 신경망, 순차 데이터를 위한 순환 신경망
- 표현 학습을 위한 오토인코더
- 데이터 생성을 위한 생산적대 신경망(GAN; Generative Adversarial Networks)