[논문리뷰] Self-Attentive Sequential Recommendation
Self-Attentive Sequential Recommendation 논문[Submitted on 20 Aug 2018] 리뷰
0. Abstract
1. Introduction
2. Related Work
3. Methodology
C.Staking Self-Attention Blocks
G. Discussion
4. Experiments
A. Datasets
G. Training Efficiency & Scalability
H. Visualizing Attention Weights
5. Conclusion
0. Abstract
○ Sequential Dynamics는 많은 현대 추천 시스템의 핵심 특징
● (당시) 최근 논문에서는 사용자 행동을 바탕으로 Context를 파악하고자 함
● 패턴 포착을 위해 두 가지 접근법이 널리 사용됨
- Markov Chains(MCs)
- Recurrent Neural Networks(RNNs;순환 신경망)
○ MCs는 다음 행동을 최근(or 몇 가지)의 행동만을 기반으로 예측할 수 있다고 가정
● 일반적으로 모델 간소화가 중요한 Sparse한 데이터셋에 가장 잘 작동
○ RNN은 (원칙적으로) 더 장기적인 의미를 탐지할 수 있도록 함
● 모델 복잡성을 감당할 수 있는 dense한 데이터셋에서 나은 성능을 보여줌
○ 본 연구의 목표: 두 가지 목표를 균형있게 달성하기
● RNN의 장점(장기적 의미 포착) + MCs의 장점(적은 수의 행동 기반으로 예측 수행)
→ SASRec(Self-Attention 기반 순차적 모델)제안
○ SASRec은 각 시간 단계에서 사용자 행동 기록 中 "관련성 있는" 항목을 식별 → 다음 항목 예측
● 실험적 연구 결과: Sparse 데이터셋과 dense한 데이터셋 모두에서 우수한 성능을 보임을 확인
● 유사한 CNN/RNN 기반 모델보다 성능 면에서 10배 더 효율적
● Attention Weights 시각화를 통해 해당 모델이 다양한 밀도의 데이터셋을 적응적으로 처리
● Activity Sequences에서 의미 있는 패턴 탐지함을 증명
1. Introduction
○ Sequential Recommender System's Goal
● 사용자 행동의 개인화된 모델(과거 활동 기반)을 최근 행동에 기반한 Context 개념과 결합하는 것
● Sequential Dynamis에서 유용한 패턴을 포착하는 것이 도전적인 과제
why? Context로 사용되는 과거 행동 수가 증가함에 따라 입력 공간 차원이 급격히 증가하기 때문
So, 해당 연구는 High Order Dynamics를 간결하게 포착하는 방법에 초점을 맞춤
○ Markov Chains(MCs): 다음 행동이 이전 행동에만 의존한다고 가정
● RecSys에서 단기 항목 전환을 설명하는 데 사용되어짐
● 강한 단순화 가정을 통해 High Sparsity 환경에서 잘 작동
● 복잡한 시나리오의 세밀한 동태성을 포착하는 데에는 한계가 존재
○ Recurrent Neural Networks(RNNs)
● 모든 이전 행동을 은닉 상태로 요약 → 이를 바탕으로 다음 행동 예측
● 표현력은 뛰어나지만, 단순한 기준선 모델을 능가하기 위해 대량의 데이터(특히 Dense한 데이터) 필요
○ Transformer
● 기계 번역 과제에서 최첨단 성능과 효율성 달성
● 기존의 순차 모델이 사용하는 합성곱 또는 순환 모듈과 달리, "Self-Attention" 메커니즘에만 기반
● 문장 내 단어 간의 구문적, 의미적 패턴 포착에 효율적
○ Transformer에 영감을 받아, 순차 추천 문제에 적용하고자 함
● 과거 모든 행동에서 맥락을 도출하는 장점(RNNs의 장점)
● 적은 수의 행동만으로 예측을 구성 가능한 장점(MCs의 장점)
● 구체적으로 각 시간 단계에서 이전 항목에 가중치를 적응적 할당(그림 1)

○ 제안된 모델의 결과
● state-of-the-art(최첨단)의 MC/CNN/RNN 기반 순차 추천 방법을 능가함
● 특히, 데이터셋 희소성의 함수로 성능 검토한 결과, 모델 성능이 패턴과 밀접하게 일치함을 확인
● Self-Attention 메커니즘을 사용함으로
- 밀도가 높은 데이터셋에서는 장거리 의존성 고려
- 희소한 데이터셋에서는 최근 활동에 중점을 둠
→ 다양한 밀도를 가진 데이터셋을 적응적으로 처리하는 데 결정적 역할
● SASRec의 핵심 구성 요소(Self-Attention Block)는 병렬 가속에 적합
→ CNN/RNN 기반 대안보다 한 차원 더 빠른 모델을 제공
● SASRec의 복잡성 확장성 분석과 주요 구성 요소의 효과를 보여주기 위한 포괄적인 Ablation Study(소거 연구) 수행
● Attention Weights를 시각화 → 모델의 동작을 질적으로 설명
2. Related Work
○ General/Temporal/Sequential Recommendation(MC 및 RNN 포함)을 논의
→ 연구 모델(Self-Attention)모듈을 포함한 Attention 메커니즘 소개
2-A General Recommendation
○ User-Item 간의 호환성을 과거 피드백(e.g. 클릭, 구매, 좋아요)를 기반으로 모델링
● 사용자 피드백은 명시적 | 암묵적일 수 있음
● 암묵적 피드백은 "non-observed'데이터(e.g. 구매하지 않은 항목)의 해석이 모호
→ 모델링이 어렵 So, point-wise, pairwise 방법이 제안됨
○ Matrix Factorization(MF; 행렬 분해)기법
● 사용자의 선호와 항목의 특성을 나타내는 잠재 차원을 찾음
→ 사용자 및 항목 임베딩간 내적을 통해 상호작용 추정
○ Item Similarity Models(ISM; 항목 유사도 모델)
● 잠재 요인을 명시적 모델링 X, 항목 간 유사도 행렬 학습
→ 사용자가 이전에 상호작용한 항목들과의 유사도를 기반으로 선호도 추정(e.g. FISM)
○ 최근에는 딥러닝 기법이 RecSys에도 도입
● About Other Paper
- 신경망을 사용해 항목 특징 추출 → Content-aware Recommendation(컨텐츠 기반 추천) 수행
- 기존 MF 대체
e.g. NeuMF: MLP(다층 퍼셉트론)을 통해 사용자 선호 추정
e.g. AutoRec: Autoencoder를 활용해 평점 예측
2-B Temporal Recommendation
○ TimeSVD++
● 시간을 여러 구간으로 나누고, 각 구간에서 사용자와 항목을 별도로 모델링
● 데이터셋의 단기 또는 장기적인 drift(시간적 변화)를 이해하는 데 필수적
e.g. 지난 10년 동안 영화 선호도는 어떻게 변화했는가?
○ Sequential Recommendation
● 시간 패턴 자체보다는 행동 순서를 고려 → 이를 독립적으로 모델링
● 즉, 순차 모델은 사용자 행동의 맥락을 최근 활동에 기반해 모델링
2-C Sequential Recommendation
○ 많은 Sequential RecSys는 연속적인 항목 간 전이 행렬 모델링하여 순차적 패턴 포착
○ FPMC
● MF 항(Term)과 항목 간 전이 항을 결합 → 장기 선호와 단기 전이를 각각 포착
● 여기서 포착된 전이는 1차 마르코프 체인(First-Order MC)에 해당
● 고차원 마르코프 체인(Higher-Order MC)은 다음 행동이 여러 이전 행동과 관련 있음을 가정
○ Caser(Convolutional Sequence Embedding)
● CNN 기반 방법
● 이전 L개의 항목 임베딩 행렬을 이미지로 간주 & 합성곱 연산 적용 → 전이 추출
○ GRU4Rec
● RNN을 사용한 사용자 시퀀스 모델링
● Gated Recurrent Units(GRU)를 사용해 세션 기반 추천을 위해 클릭 시퀀스 모델링
● 개선된 버전의 경우 Top-N 추천 평가 지표의 성능을 향상
● But RNN의 단계별 의존성은 비효율적일 수 있음
● So, Session-Parallelism 기술 제안
2-D Attention Mechanisms
○ Attention 메커니즘은 이미지 캡셔닝, 기계 번역 같은 다양한 작업에 효과적으로 사용됨
● 기본 아이디어: 모델이 "관련성 있는" 입력 부분에 순차적으로 집중해 출력 생성
● 종종 해석 가능성이 높다는 장점 존재
○ AFM(Attential Factorization Machines)
● 컨텐츠 기반 추천을 위해 각 피처 상호작용의 중요도 학습
● But 해당 모델에서 Attention은 기존 모델(RNN, FM 등)에 추가된 보조 요소로 사용됨
3. Methodology
○ 순차 추천 환경에서는 사용자의 행동 시퀀스가 주어지고, 다음 항목을 예측하는 것이 목표
● 사용자의 행동 시퀀스
$$ S_{u} = (S^{1}_{u}, S^{2}_{u}, ..., S^{|S_{u}|}_{u}) $$
● 학습 과정에서 시간 단계 t에서 모델은 이전 t개의 항목에 따라 다음 항목을 예측
○ 모델의 입력(훈련 시퀀스)을 첫 번째 같이, 출력은 이와 '이동된' 시퀀스(두 번째)와 같이 간주하는 것이 편리
$$ (S^{1}_{u}, S^{2}_{u}, ..., S^{S_{u}-1}_{u}) $$
$$ (S^{2}_{u}, S^{3}_{u}, ..., S^{|S_{u}|}_{u}) $$
○ 해당 섹션에서는 임베딩 레이어, Self-Attention Block, Prediction Layer를 통해 순차 모델 구축법 설명
※ Table1의 경우 표기법에 관하여 정의

3-A Emdedding Layer
○ 훈련 시퀀스를 고정된 길이 n의 시퀀스로 변환
$$ s = (s_{1}, s_{2}, ..., s_{3}) $$
※ n: 모델이 처리할 수 있는 최대 길이
● If 시퀀스 길이 > n → 가장 최근 n개의 행동 고려
● If 시퀀스 길이 < n → 왼쪽에 padding 항목을 반복적 추가하여 길이를 n으로 맞춤
○ 항목 임베딩 행렬을 생성하고 입력 임베딩 행렬을 가져옴
※ d: 잠재 차원 수
$$ \textup{Item Embedding Matrix} M \in \mathbb{R}^{|I| *d} $$
$$ \textup{Input Embedding Matrix} E \in \mathbb{R}^{n *d} $$
$$ E_{i} = M_{s_{i}} $$
● Padding 항목의 임베딩은 상수 0 벡터 사용
● Self-Attention Model은 합성곱(Convolutional) 모듈을 포함하지 않기 때문에 이전 항목의 위치를 인식 못함
→ 학습 가능한 위치 임베딩을 입력 임베딩에 추가
$$ P \in \mathbb{R}^{n*d} $$

● 사용된 고정 위치 임베딩을 시도 → 성능이 저하되는 것을 확인
● 실험에서 위치 임베딩 효과를 정량적, 정성적으로 분석
3-B Self-Attention Block
○ 스케일 조정 점곱 어텐션은 아래와 같이 정의

※ Q는 쿼리, K는 키, V는 값(각 행이 항목)
● Attention Rayer는 모든 값의 가중합을 계산
- 쿼리 i와 값 j 사이의 가중치는 쿼리(i)와 키(j)의 상호작용과 관련됨
● root d는 차원이 높을 때 내적 값이 지나치게 커지는 것을 방지
● NLP 작업(e.g. 기계 번역)에서는 일반적으로 K = V를 사용
- 최근 제안된 Self-Attention 방식은 동일한 객체를 쿼리, 키, 값으로 사용
● 해당 논문에서는 Self-Attention 연산은 임베딩 E_{b}를 입력으로 받아 선형 투영을 통해 세 개의 행렬로 변환
→ Attention Rayer에 전달
$$ S = SA(\hat{E}) = \textup{Attention}(\hat{E}W^{Q}, \hat{E}W^{K}, \hat{E}W^{V}) $$
※ 여기서 투영은 모델의 유연성을 높이며 비대칭 상호작용을 학습할 수 있게 함
○ Causality(인과성)
● Sequential의 특성 때문에 모델은 (t+1)번째 항목을 예측할 때 t번째까지의 항목만 고려해야 함
● Self-Attention Rayer의 t번째 출력은 S_{t}는 이후 항목의 임베딩 포함 So, 모델이 적절히 학습되지 않을 수 있음
● So, 아래의 모든 연결을 금지하는 방식으로 Attention 수정
$$ Q_{i} \textup{&} K_{j} (j > i) $$
○ Point-Wise Feed-Foward Network(포인트-와이즈 피드포워드 네트워크)
● Self-Attention은 적응적 가중치로 이전 항목의 임베딩을 모두 집계 가능
● But 여전히 선형 모델
● 모델에 비선형성을 부여하고 다른 잠재 차원 간의 상호작용 고려
● So, 모든 S_{i}에 동일하게 포인트-와이즈 2층 피드 포워드 네트워크 적용
$$ F_{i} = \textup{RELU}(S_{i}W^{(1)}+ b^{(1)})W^{(2)} + b^{(2)} $$
※ 여기서 W(1), W(2)는 d*d 행렬이고 b(1),b(2)는 d-차원 벡터
※ S_{i}와 S_{j}(i ≠ j)간의 상호작용 방지
3-C Staking Self-Attention
○ 첫 번째 Self-Attention Block 이후 F_{i}는 본질적으로 이전 항목의 임베딩을 모두 집계
● 추가적인 Self-Attention Block을 통해 더 복잡한 항목 전이를 학습 가능
● 네트워크가 깊어지면서 과적합, 불안정한 학습, 더 많은 학습 시간과 갗은 문제가 악화될 수 있음
● So, 이를 완화하기 위해 레이어 정규화, 드롭아웃, 잔차 연결 등을 적용


○ 적용 방법
● 잔차 연결(Residual Connections): 저차원 특징을 고차원으로 전달 → 유용한 정보를 손쉽게 사용하도록 함
● 레이어 정규화(Layer Normalization): 입력을 정규화하여 하여 학습을 안정화 & 가속화

● 드롭아웃(Dropout): 일부 뉴런을 무작위로 꺼서 과적합 방지
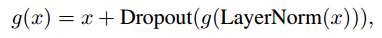
3-D Prediction Layer
○ 여러 블록을 통해 적응적으로 추출된 정보 F_{t}^{(b)}를 기반으로 아래 항목의 관련성을 예측
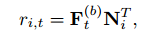
※ N = 항목 임베딩 행렬, r_{i},{t}의 값이 높을 수록 해당 항목이 다음 항목일 가능성이 높음
※ 즉, r_{i},{t}는 t번째까지의 항목 시퀀스가 주어졌을 때, i번 항목이 다음 항목일 관련성
※ 점수(r_{i},{t})를 정렬해 추천을 생성 가능

● b개의 Self-Attention Block을 통해 이전에 소비된 항목들에 정보를 적응적 & 계층적으로 추출
→ MF 레이어를 채택하여 항목 i의 관련성을 예측
○ Shared Item Embedding
● 모델 크기를 줄이고 과적합 완화를 위해, 단일 항목 임베딩 M만 사용

● 동질적(Homogeneous) 항목 임베딩을 사용할 경우, 내적은 비대칭적인 항목 전이를 나타내지 못할 수 있음
e.g. 항목 i가 j 이후에 자주 구매되지만, 반대의 경우는 드문 경우
● So, 기존 방법(FPMC 등)은 이질적(Heterogeneous) 항목 임베딩을 사용하는 경향이 있음
● But, 해당 연구에서의 모델은 비선형 변환을 학습 So, 위의 문제가 없음
e.g. 피드포워드 네트워크는 동일한 항목 임베딩으로도 쉽게 비대칭성을 달성 가능
● 실험 결과, 공유 항목 임베딩을 사용하는 것이 모델 성능을 크게 향상시킨다는 것을 확인


○ Explicit User Modeling
● 개인화된 추천을 제공하기 위해 기존의 방법은 두 가지 접근법 중 하나를 사용
- 사용자 선호도를 나타내는 명시적 사용자 임베딩을 학습(MF,FPMC, Caser 등)
- 사용자의 이전 행동을 고려해 방문한 항목들의 임베딩으로부터 암묵적 사용자 임베딩을 유도
(FISM, Fossil, GRU4Rec 등)
● SASRec은후자의 범주이며, 사용자의 모든 행동을 고려해 F^{(b)}_n 임베딩 생성
※ 명시적 사용자 임베딩을 마지막 레이어에 추가할 수도있음
e.g. 여기서 U는 사용자 임베딩 행렬, But 명시적 사용자 임베딩을 추가해도 성능 개선이 없음을 확인
→ 모델이 이미 사용자의 모든 행동을 고려하기 때문인 것으로 추측

3-E Network Training
○ 각 사용자 시퀀스(마지막 행동 제외)를 잘라내기 | 패딩을 통해 고정된 길이로 변환
● 시간 단계 t에서 기대 출력 o_{t}를 정의
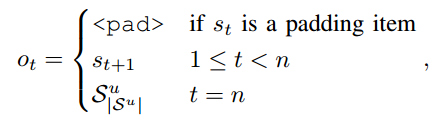
※ <pad>는 패딩 항목
● 시퀀스 s를 입력으로, 대응하는 시퀀스 o를 기대 출력으로 사용
● 목적 함수: 이진 교차 엔트로피 손실
※ o_t = <pad>인 경우는 무시

● Adam 옵티마이저를 통해 최적화(적응형 모멘트 추정을 사용하는 SGD의 변형)
● 각 epoch에서 각 시퀀스의 각 시간 단계에 대해 하나의 부정항목(j)를 무작위 생성
3-F Complexity Analysis
○ Space Complexity
● 총 매개변수

● 이는 d가 일반적으로 작은 추천 문제에서 사용자 수에 비례하지 않으므로 다른 방법과 비교해 적당함
e.g. FPMC의 경우

○ Time Complexity
● 모델의 주요 계산 복잡도
- Self-Attention Rayer와 Feed-Foward Network에서 비롯됨
※ 주로 O(n^{2} * d)인 Self-Attention Rayer가 지배적

● SASRec의 경우 각 Self-Attention Rayer의 계산이 완전히 병렬화 가능
● So, GPU 가속에 적합
● But, RNN 기반 방법(e.g. GRU4Rec)은 시간 단계 종속성으로 O(n) 시간의 순차적 계산을 요구
● 실험 결과, 논문의 모델은 GPU를 사용할 경우 RNN 및 CNN 기반 방법보다 10배 이상 빠름
※ 테스트 중에는 각 사용자에 대해 F^{(b)}_{n} 임베딩 계산 → 표준 MF 방법과 동일한 방식으로 프로세스 진행
※ O(d)는 항목에 대한 선호도를 평가하는 데 소요
○ Handing Long Sequences
● 실험을 통해 모델의 효율성을 확인 But, 긴 시퀀스에는 확장이 불가할 수 있음
● So, 이 후 아래와 같은 옵션을 탐색 가능
- restricted Self-Attention을 사용해 모든 행동이 아닌 최근 행동에만 주목하고, 먼 행동은 상위 레이어에서 고려
- 긴 시퀀스를 짧은 세그먼트로 분할
3-G Discussion
○ SASRec은 일부 고전적인 CF 모델의 일반화된 형태로 볼 수 있음
● 또한 기존 방법과 논문의 접근법이 시퀀스 모델링을 처리하는 방식을 개념적으로 논의
○ Reduction to Existing Models(Factorized Markov Chains; FMC)
● FMC는 1차 항목 전이 행렬 분해하여 이전 항목 i 에 따라 다음 항목 j를 예측
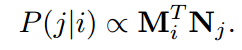
● Self-Attention Block을 제거, 비공유 항목 임베딩 사용, 위치 임베딩 제거
→ SASRec은 FMC로 축소 가능
● 또한 명시적 사용자 임베딩을 추가하면 SASRec은 FPMC와 동일해짐

○ Reduction to Existing Models(Factorized Item Similarity Models; FISM)
● FISM: 사용자가 이전에 소비한 항목과의 유사성을 고려해 항목 i에 대한 선호 점수를 추정

● 하나의 Self-Attention Rayer, 균일한 Attention weight를 항목에 설정, 비공유 항목 임베딩 사용, 위치 임베딩 제거
→ SASRec은 FISM으로 축소됨
● So, SASRec은 차별적이고 계층적인 순차 항목 유사도 모델로 간주 가능
○ MC-Based Recommendation
● MC는 다음 항목이 이전 L개의 항목에만 의존한다고 가정, 로컬 순차적 패턴을 효과적으로 포착 가능
● 기존 MC 기반 추천 방법은 1차 MC(FPMC, HRM, TransRec) 또는 고차 MC(Fossil, Vista, Caser)에 의존
● 1차 MC 기반 방법은 희소 데이터셋에서 최고의 성능을 내지만, 고차 MC 기반 방법은 아래의 한계가 존재
1) MC 순서 L을 학습 전에 지정해야 하며 적응적으로 선택 불가
2) 성능 및 효율성이 L에 따라 잘 확장되지 않음 So, L은 일반적으로 작음(e.g. 5 미만)
● SASRec의 경우 첫 번째 문제 해결 → 희소 데이터셋에서는 마지막 항목에만 집중
& 밀집 데이터셋에서는 더 많은 항목에 주목하는 방식 So, 이전 항목에 적응적으로 주목
● 또한, n개의 이전 항목을 기반으로 하며, 이전 항목으로 확장 가능하여, 학습 시간의 적당한 증가와 함께 성능 이점
○ RNN-Based Recommendation
● RNN을 사용해 사용자 행동 시퀀스를 모델링
● 최근 연구에서 시퀀스를 모델링하는 데 적합 But, CNN 및 Self-Attention이 일부 순차적 설정에서 더 효과적임을 증명
● 논문의 Self-Attention 기반 모델은 시퀀스 모델링을 위한 대안으로 간주될 수 있는 항목 유사도 모델에서 파생 가능
● RNN은 시간 단계 간 병렬 계산에서 비효율적 & 입력노드에서 관련 출력 노드까지의 최대 경로 길이가 O(n)
● But, SASRec은 최대 경로 길이가 O(1)로 장기적인 의존성 학습에 유리할 수 있음
4. Experiments
○ 해당 섹션에서는 실험 환경과 실증적 결과를 제시, 실험은 아래 질문에 답하기 위해 설계됨
RQ1: SASRec이 CNN/RNN 기반 방법을 포함한 최신 모델들을 능가하는가?
RQ2: SASRec 아키텍처의 다양한 구성 요소가 어떤 영향을 미치는가?
RQ3: SASRec의 학습 효율성과 확장성(특히 n과 관련하여)은 어떠한가?
RQ4: Attention weight가 위치나 항목 속성과 관련된 의미 있는 패턴을 학습 가능한가?
4-A Datasets
○ 실제 Application에서 얻은 4가지 데이터셋으로 평가
● 데이터셋은 도메인, 플랫폼, 희소성에서 매우 다름
○ Amazon
● Amazon.com에서 크롤링된 대규모 상품 리뷰 데이터셋
● 최상위 상품 카테고리는 별도의 데이터셋으로 취급(Beauty와 Games 카테고리를 고려)
● 선택한 카테고리의 데이터셋은 높은 희소성과 변동성이 있음
○ Steam
● Steam에서 크롤링한 새로운 데이터셋
● 사용자 플레이 시간, 가격 정보, 미디어 점수, 개발자 정보 등에 관한 정보 포함
○ MovieLens
● CF 알고리즘 평가를 위한 널리 사용되는 벤치마크 데이터셋
● 백만 개의 사용자 평점을 포함하는 MovieLens-1M 버전을 사용
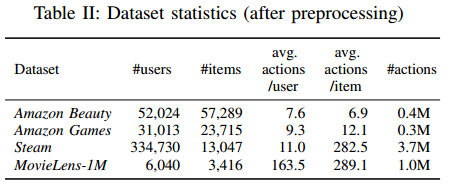
○ 모든 데이터셋에서 리뷰 | 평점의 존재를 암묵적 피드백으로 간주
● 즉, 사용자가 항목과 상호작용
● TimeStamp를 사용해 행동의 순서를 결정
● 5개 미만의 관련 행동을 가진 사용자와 항목은 제외
● 사용자의 과거 시퀀스 S_{u}는 아래의 3 부분으로 분할
- 가장 최근 행동 S^{|S_{u}|}_{u}: 테스트용
- 두 번째로 최근 행동 S^{|S_{u}|-1}_{u}: 검증용
- 나머지 행동: 학습용
● 테스트 시 입력 시퀀스는 학습 데이터와 검증 행동을 포함
4-B Comparison Methods
○ 세 개의 그룹으로 추천 기준선 포함
○ 일반 추천 방법: 사용자 피드백만 고려
● PopRec: 항목의 인기도(관련 행동 수)에 따라 항목을 순위화
● BPR(Bayesian Personalized Ranking)
: 암묵적 피드백으로부터 개인화된 순위를 학습하는 방법, 편향된 행렬 분해를 기반으로 추천 생성
○ 1차 마르코프 체인 기반 순차 추천 방법
● FMC: 1차 마르코프 체인 방법, 항목 전이 행렬을 분해해 마지막 방문 항목에 따라 추천 생성
● FPMC: 행렬 분해와 1차 마르코프 체인을 결합해 장기 선호도와 항목 간 전이를 모두 포착
● TransRec: 최신 1차 순차 추천 방법, 사용자를 현재 항목에서 다음 항목으로의 전이를 캡처하는 번역 벡터로 모델링
○ 딥러닝 기반 순차 추천 방법: 여러 이전항목을 고려
● GRU4Rec: 세션 기반 추천을 위해 RNN 사용하여 사용자 행동 시퀀스를 모델링하는 방법
각 사용자의 피드백 시퀀스를 세션으로 처리
● GRU4Rec+: GRU4Rec개선 버전, 다른 손실 함수와 샘플링 전략을 채택하여 Top-N 추천 성능을 향상
● Caser(Convolutional Sequence Embeddings)
: 최근 L개의 항목 임베딩 행렬에 합성곱 연산을 적용해 고차 마르코프 체인을 캡처
※ PRME, HRM, Fossil 같은 다른 추천 방법은 위 기준선에서 성능이 우수한 데이터셋에서 이미 능가 So, 비교 제외
※ TimeSVD++ 및 RRN 같은 시간 기반 추천 방법도 설정과 다르기 때문에 포함하지 않음
4-C Implementation Details
○ SASRec의 기본 아키텍처에서 b = 2개의 Self-Attention 블록과 학습된 위치 임베딩 사용
● 임베딩 레이어와 예측 레이어의 항목 임베딩은 공유
● Adam 옵티마이저 사용, 학습 속도 = 0.001, 배치 크기 = 128로 설정
● MovieLens-1M의 Dropout 비율은 0.2로 설정 나머지는 희소성으로 0.5로 설정
● 최대 시퀀스 길이(n)은 MovieLens-1M에서 200, 나머지는 50으로 설정
4-D Evaluation Metrics
○ Top-N 성능 평가를 위해 Hit Rate@10과 NDCG@10 두 가지 지표 채택
● Hit@10: 실제 다음 항목이 상위 10개의 항목 中 하나에 속하는 빈도 측정
● NDCG@10: 위치에 민감한 지표로, 높은 순위에 더 큰 가중치를 부여
● 각 사용자에 대해 100개의 부정 항목을 무작위로 샘플링 & 실제 항목과 이를 순위화하여 평가 수행
4-E Recommendation Performance
○ 표3은 네 데이터셋에서 모든 방법의 추천 성능을 보여줌(RQ1)
● Non-neural 방법: 희소 데이터셋에서 더 우수
● Neural 방법: 밀집 데이터셋에서 우수
● why? 신경망이 높은 차수 전이를 캡처하는 데 더 많은 매개변수를 가지기 때문,
Sparse한 환경에서는 과적합되기 쉽기 때문
○ SASRec은 희소/밀집 데이터셋 모두에서 모든 기준선 능가
● 가장 좋은 성능의 기준선에 비해 평균적으로 6.9%의 Hit Rate와 9.6%의 NDCG 개선 달성
● SASRec이 데이터셋에 따라 적응적으로 항목 범위에 주목할 수 있기 때문일 가능성 多
e.g. 희소 데이터셋에서는 마지막 항목만, 밀집 데이터셋에서는 더 많은 항목을 고려

4-F Ablation Study
※ 아키텍처의 여러 구성 요소가 성능에 미치는 영향 분석을 위해 진행(RQ2)

○ 표 IV는 d = 50일 때 기본 방법과 8가지 변형의 성능을 보여줌 각 변형의 영향은 아래와 같음

(1) Remove PE(Positional Embedding)
● 위치 임베딩 P 없이 Attention Weight는 항목임베딩에만 의존
● 즉, 모델은 사용자의 과거 행동 기반 추천을 하지만, 순서는 중요하지 않음
● 해당 변형은 사용자 시퀀스가 일반적으로 짧은 희소 데이터셋(Beauty)에서 기존보다 좋음
But, 다른 밀집데이터셋에서는 낮은 성능
(2) Unshared IE(Item Embedding)
● 두 개의 항목 임베딩을 사용하는 경우 일관되게 성능이 저하(Maybe 과적합 때문)
(3) Remove RC(Residual Connections)
● 잔차 연결을 제거하면 성능이 크게 저하
● why? 낮은 레이어의 정보가 최종 레이어로 쉽게 전달되지 못하기 때문
● 해당 변형은 희소 데이터셋에서 추천을 만드는 데 매우 유용
(4) Remove Dropout
● 모델을 정규화하여 테스트 성능을 향상 가능 + 희소 데이터셋에서 효과적
● 결과는 또한 밀집 데이터셋에서는 과적합 문제가 덜 심각하다는 것을 암시
(5)-(7) Number of blocks
● 블록이 없는 경우 모델이 마지막 항목에만 의존 So, 결과가 열등
● 블록이 하나인 경우 적절한 성능 But 두 개의 블록(기본 모델)을 사용하는 것이 밀집 데이터셋에서 성능 향상
● 세 개의 블록을 사용하는 경우 기본 모델과 유사한 성능을 보여줌
(8) Multi-head
● Multi-head Attention(각 d/h-차원의 하위 공간에 Attention 적용)이 유용
● 두 개의 헤드를 사용하는 경우, 성능은 일관되게 단일 헤드 Attention보다 약간 낮음
● 문제에서 d가 작아(d= 512인 Transformer와 비교) 작은 하위 공간으로 분해하기에 적합하지 않기 때문으로 추측
4-G Training Efficiency & Scalability
○ Training Efficiency
● 모델의 학습 속도와 수렴시간을 평가
● 최대 길이 n 측면에서 모델의 확장성 조사
● SASRec은 한 epoch에서 모델 업데이트에 1.7초만 소요(Caser보다 11배, GRU4Rec+보다 18배 빠름)
● SASRec은 ML-1M에서 약 350초만에 최적 성능에 도달

○ Scalability
● 표준 행렬 분해(MF)방법과 마찬가지로 사용자, 항목, 행동의 총 수에 따라 선형적으로 확장됨
● 최대 길이(n)은 확장성 문제일 수 있지만 GPU로 계산을 효과적으로 병렬화 가능
● Table V에 따르면, n이 증가할수록 성능이 크게 향상(n=500에서 포화)
● SASRec은 수백 개의 행동이 포함된 사용자 시퀀스를 쉽게 처리 가능(일반적 리뷰 및 구매 데이터셋에 적합)

4-H Visualizing Attention Weights
※ t단계에서, 모델의 Self-Attention 메커니즘은 위치 임베딩과 항목 임베딩에 따라 첫 번째 t 항목에 가중치를 적응적 할당
○ Attention on Positions
● 그림 4는 마지막 15개의 시간 단계에서 마지막 15개의 위치에 대한 평균 Attention weight를 보여줌
※ padding 항목의 영향을 피하기 위해 유효한 가중치 수를 분모로 사용

○ (a) vs (c)
● 희소 데이터셋(Beauty)에서는 최근 항목에 더 집중, 밀집 데이터셋(ML-1M)에서는 덜 최근 항목에 집중
● So, SASRec이 희소 및 밀집 데이터셋 모두를 적응적으로 처리할 수 있게 하는 핵심 요인
○ (b) vs (c)
● PE를 사용하지 않은 경우, Attention weight는 이전 항목에 대해 본질적으로 균일하게 분포
● 기본 모델(c)는 위치에 민감 & 최근 항목에 집중하는 경향
○ (c) vs (d)
● 계층적 모델인 SASRec은 블록 간 Attention이 어떻게 달라지는지를 보여줌
● 높은 레이어의 Attention은 최근 위치에 더 집중 ← 첫 번째 self-Attention 블록이 이미 모든 이전 항목 고려했기 때문
○ Attention Between Items
● MovieLens-1M에서 영화 카테고리 사용 → 두 개의 비공통 세트를 무작위 선택
● 첫 번째 세트는 쿼리로, 두 번째 세트는 키로 사용
● Figure 5의 hitmap은 평균 Attention weight를 보여주며, 대각선 블록 형태를 나타냄
(= Attention 메커니즘이 유사한 항목을 식별하고, 더 높은 가중치를 할당하는 경향이 있음을 나타냄)

5. Conclusion
○ 다음 항목 추천을 위한 새로운 Self-Attention 기반 순차 모델인 SASRec을 제안
○ SASRec은 recurrent 또는 Convolutional 연산 없이 전체 사용자 시퀀스 모델링
+ 예측을 위해 소비된 항목을 적응적으로 고려
○ 희소/밀집 데이터셋 모두에서 최신의 기준선을 능가하며 빠른 것을 실험을 통해 확인
○ 향후 연구에서는 풍부한 맥락 정보(e.g. 체류 시간, 행동 유형, 위치, 기기 등)을 통합
+ 매우 긴 시퀀스를 처리하는 접근법(e.g. Click data)를 조사할 계획