SK networks AI Camp - 야구 데이터 분석해보기(1) feat. Lotte giants
24년 7월 8일부터 진행중인 SK networks AI Camp에서 많은 것들을 배웠습니다.
[7월 ~ 8월 배운 내용]
Python, Database(Docker, DBeaver), Crawling(BeautifulSoup,Selenium), 리눅스 명령어, 화면구현
아무래도 짧은 시간동안 많은 것을 배우다보니 단기 속성 과외와 같은 느낌처럼 진도가 너무 빠릅니다.
그래서 스터디를 하고 미니나 파이널 프로젝트와 별개로 토이 프로젝트를 하고 있습니다.
배운 걸 써 볼 수 있는 것을 해봐야겠다 싶어서 찾아보다가 야구 데이터 분석을 해보자는 생각이 들었습니다.
에자일 방법론을 사용하여 점차 늘려나가는 것으로 해보겠습니다.
[제일 아래 코드 와 코드 파일 넣어뒀습니다]

[계획]
1. Crawling을 통하여 롯데자이언츠 홈페이지에서 필요한 데이터 크롤링해오기
* 이전에 BeautifulSoup로 진행하여 Selenium 써보기
○ 공식 홈페이지
https://www.giantsclub.com/html/?pcode=288
팀 타자 > 선수기록 > 기록실 | 롯데자이언츠
- 메뉴 - 연인팩 : 12,600원 크리스피팩 : 14,100원 실속팩 : 18,100원
www.giantsclub.com
○ 끌어올 데이터 : 2024년 타자, 투수의 기록
○ 이 후 추가할 데이터
: 2008년 ~ 2023년 상대팀/홈&원정/주&야간/월&일&요일/전반기&후반기별 선수 데이터
○ DBeaver를 통하여 MySQL 및 Docker를 사용
○ 초기 Streamlit 사용 | Django를 활용하여 웹 구현
○ 데이터 분석&머신/딥러닝의 경우 배우면 추가로 진행 예정
- Crawling을 통해 2024년 타자 | 투수 데이터 불러오고 데이터 전처리 후 DB에 저장
* (파일: baseball.ipynb)
○ Import
import pandas as pd
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import Keys, ActionChains
import pyperclip
from sqlalchemy import create_engine
import re
from collections import defaultdict○ Crawling
● 접속
driver = webdriver.Chrome()
url = "https://www.giantsclub.com/html/?pcode=288"
driver.get(url)
driver.implicitly_wait● 타자 데이터 불러오기
1. X.PATH를 사용하여 간단하게 페이지 넘어가는 버튼 찾기 + 데이터 저장
2. time.sleep(1.5) : 바로 넘어가니 데이터를 저장 못하여 추가
hitter_data, pitcher_data = [], []
for i in range(3): #3페이지까지
if i == 1:
driver.find_element(By.XPATH, value='//*[@id="div_data"]/div[2]/a[2]').click()
time.sleep(1.5)
elif i == 2:
driver.find_element(By.XPATH, value='//*[@id="div_data"]/div[2]/a[3]').click()
time.sleep(1.5)
hitter_data.append(driver.find_element(By.XPATH, '//*[@id="tbl-rank"]').text.split('\n'))● 투수 데이터 불러오기
1. 투수 데이터를 찾을 때 그냥 페이지 자체를 넘겨줌
2. 이하 타자 데이터와 동일
driver.get('https://www.giantsclub.com/html/?pcode=289')
driver.implicitly_wait(5)
time.sleep(1.5)
for i in range(3): #3페이지까지
if i == 1:
driver.find_element(By.XPATH, value='//*[@id="div_data"]/div[2]/a[2]').click()
time.sleep(1.5)
elif i == 2:
driver.find_element(By.XPATH, value='//*[@id="div_data"]/div[2]/a[3]').click()
time.sleep(1.5)
pitcher_data.append(driver.find_element(By.XPATH, '//*[@id="tbl-rank"]').text.split('\n'))
# 저장될때까지 기다렸다가 창 자동 종료
time.sleep(2)
driver.close()● 불러온 데이터 : 빨간 부분 1페이지~ 3페이지(타자, 투수 총 6개)

● 불러온 데이터(hitter_data, pitcher_data)


● 트러블슈팅1)
1. time.sleep() 대신에 implicitly_wait()을 사용함. 그 결과 데이터를 못받은 경우가 발생
- driver.implicitly_wait(10) : 10초안에 웹페이지를 load 하면 바로 넘어가거나, 10초를 기다림
- time.sleep(10) : 10초를 기다림
참고링크 : https://balsamic-egg.tistory.com/16
[파이썬] driver.implicitly_wait 와 time.sleep 차이점
driver.implicitly_wait(10) 과 time.sleep(10) 의 차이점은 뭘까요? 결론부터 얘기하자면, driver.implicitly_wait(10) : 10초안에 웹페이지를 load 하면 바로 넘어가거나, 10초를 기다림. time.sleep(10) : 10초를 기다림.
balsamic-egg.tistory.com
[잘못된 데이터를 받아온 코드]
# 데이터를 잘못 받아온 코드
div_data = []
for i in range(3): #3페이지까지
if i == 0:
div_data.append(driver.find_element(By.ID, 'div_data').text)
driver.implicitly_wait(3)
elif i == 1:
driver.find_element(By.XPATH, value='//*[@id="div_data"]/div[2]/a[2]').click()
div_data.append(driver.find_element(By.ID, 'div_data').text)
driver.implicitly_wait(3)
elif i == 2:
driver.find_element(By.XPATH, value='//*[@id="div_data"]/div[2]/a[3]').click()
div_data.append(driver.find_element(By.ID, 'div_data').text)
driver.implicitly_wait(3)2. div_data.append(driver.find_element(By.ID, 'div_data').text)를 앞에 적어서 3번째 페이지는 안 받아지고 1번째 페이지는 중복해서 받아짐[time.sleep() 쓰기 전 사용한 방법]
● time.sleep()을 사용하여 해결함. 그냥 좀 기다려주면 알아서 잘 해주는 착한 친구
○ 데이터 처리
● 필요 없는 데이터 정리와 키워드, 팀 합계, 선수들 기록 정리 함수
- result_pitcher와 result_hitter에 딕셔너리로 {total: [전체 기록], 'keywords' : [키워드], 'player' :[선수 기록]} 담기
def clean_data(data):
processed_data = []
for record in data:
filtered_record = [item for item in record if item not in ('정렬선택', '롯데자이언츠 팀 타자 기록', '오름차순', '롯데자이언츠 팀 투수 기록', '내림차순')]
processed_data.append(filtered_record)
return processed_data
# 키워드, 팀 합계, 선수들 기록 정리
def process_mod(data):
total = []
keywords = []
player = []
for table in data:
for i, row in enumerate(table):
# starts with '합계'인 인덱스 찾기
if row.startswith('합계'):
# 데이터 나누기
total_data = table[i].split()
keywords_data = table[:i]
player_data = table[i + 1:]
# '합계' 제거 ==> total_data
total_data = [item for item in total_data if item != '합계']
# '순위' and '선수명' 제거 ==> keywords_data
keywords_data = [
' '.join(item for item in row.split() if item not in ('순위', '선수명'))
for row in keywords_data
]
# '포지션' 제거 ==> keywords_data
keywords_data = [
' '.join(item for item in row.split() if item != '포지션')
for row in keywords_data
]
# Extend the results
total.append(' '.join(total_data)) # Join back to a single string
keywords.extend(keywords_data)
player.extend(player_data)
break # Only process the first occurrence of '합계'
return {
'total': total,
'keywords': keywords,
'player': player
}
● 함수 실행
result_pitcher = process_mod(mod_pitcher)
result_hitter = process_mod(mod_hitter)

● 정규화로 첫 문자(선수이름 앞 숫자)와 공백 제거함수 + 선수기록 합치는 코드
# 정규화를 통한 선수 앞 숫자 제거
def remove_initial_numbers(player_list):
cleaned_player_list = []
for player in player_list:
# string의 첫 문자와 공백 제거
cleaned_player = re.sub(r'^\d+\s+', '', player)
cleaned_player_list.append(cleaned_player)
return cleaned_player_listresult_hitter['player'] = remove_initial_numbers(result_hitter['player'])
result_pitcher['player'] = remove_initial_numbers(result_pitcher['player'])*아래 기록 합치기 코드는 모듈화하면 좋을 듯
# 타자
# 기록 한개로 합치기
player_dict = defaultdict(list)
for entry in result_hitter['player']:
# 첫번째 공백으로 항목 분할
first_word, rest_of_entry = entry.split(maxsplit=1)
player_dict[first_word].append(rest_of_entry)
# 최종 결과
result_hitter['player'] = [f"{key} {', '.join(value)}" for key, value in player_dict.items()]
# 투수
# 기록 한개로 합치기
player_dict = defaultdict(list)
for entry in result_pitcher['player']:
# Split the entry by the first space
first_word, rest_of_entry = entry.split(maxsplit=1)
player_dict[first_word].append(rest_of_entry)
# Create the final result list
result_pitcher['player'] = [f"{key} {', '.join(value)}" for key, value in player_dict.items()]
● 특정 인덱스를 삭제 + 쉼표 제거
# 함수 정의
def remove_elements_from_string(string, indices):
parts = string.split()
# indices는 삭제할 요소의 인덱스를 가진 리스트
return ' '.join(part for idx, part in enumerate(parts) if idx not in indices)
# 결과 리스트 생성
new_result = []
for entry in result_hitter['player']:
# 각 문자열에 대해 2, 14, 25번째 인덱스의 요소를 삭제
new_entry = remove_elements_from_string(entry, {1, 13, 24})
new_result.append(new_entry)
result_hitter['player'] = new_result
# 쉼표 제거
cleaned_h_player = [entry.replace(',', '') for entry in result_hitter['player']]
cleaned_p_player = [entry.replace(',', '') for entry in result_pitcher['player']]
result_hitter['player'] = cleaned_h_player
result_pitcher['player'] = cleaned_p_player
● keywords, total 내용정리
- keywords에 데이터 추가 : 선수명을 제거했던 상태라 pd에 넣을 때 인덱스를 맞춰주기 위해 '선수명' 추가
# keywords
result_hitter['keywords'] = ['선수명']+ result_hitter['keywords']
result_pitcher['keywords'] = ['선수명']+ result_pitcher['keywords']
# total
result_hitter['total'] = [item for sublist in (s.split(' ') for s in result_hitter['total']) for item in sublist]
result_hitter['total'] = ['전체']+ result_hitter['total']
result_pitcher['total'] = [item for sublist in (s.split(' ') for s in result_pitcher['total']) for item in sublist]
result_pitcher['total'] = ['전체']+ result_pitcher['total'][정리 후 데이터]
- result_hitter



- result_pitcher



● 트러블 슈팅 2)
- 투수의 소화 이닝 파트의 경우 40 1/3등 공백으로 나누어져있는데 공백으로 끊어서 데이터 양이 늘어남
- 13번째와 14번째 데이터가 나눠졌기에 40 1/3처럼 이루어진 데이터의 len은 31이였음.
- 해결 : 만약 len이 31이면 13번과 14번의 데이터를 하나로 합치기
# 데이터 처리
processed_players = []
for player_str in result_pitcher['player']:
parts = player_str.split(' ')
if len(parts) == 31:
# 13번째와 14번째 요소를 합침
parts[12] = parts[12] + ' ' + parts[13]
# 14번째 요소를 제거
del parts[13]
processed_players.append(parts)
○ 데이터를 데이터 프레임에 넣기
● 행 = keywords, 열에 선수 데이터를 공백으로 끊어서 하나씩 넣기, 마지막에 전체 기록 넣기
# DataFrame 생성
p_df = pd.DataFrame(processed_players)
# 행을 keywords로 설정
p_df.columns = result_pitcher['keywords']
# 'result['player']'의 문자열을 공백으로 나눠서 열을 생성
player_split_data = [player.split(' ') for player in result_hitter['player']]
# DataFrame 생성
h_df = pd.DataFrame(player_split_data)
# 'result['keywords']'를 행으로 추가
h_df.columns = result_hitter['keywords']
p_df.loc[len(p_df)] = result_pitcher['total']
h_df.loc[len(h_df)] = result_hitter['total']
● 데이터 프레임에 넣은 결과
- p_df(투수 기록), h_df(타자기록)

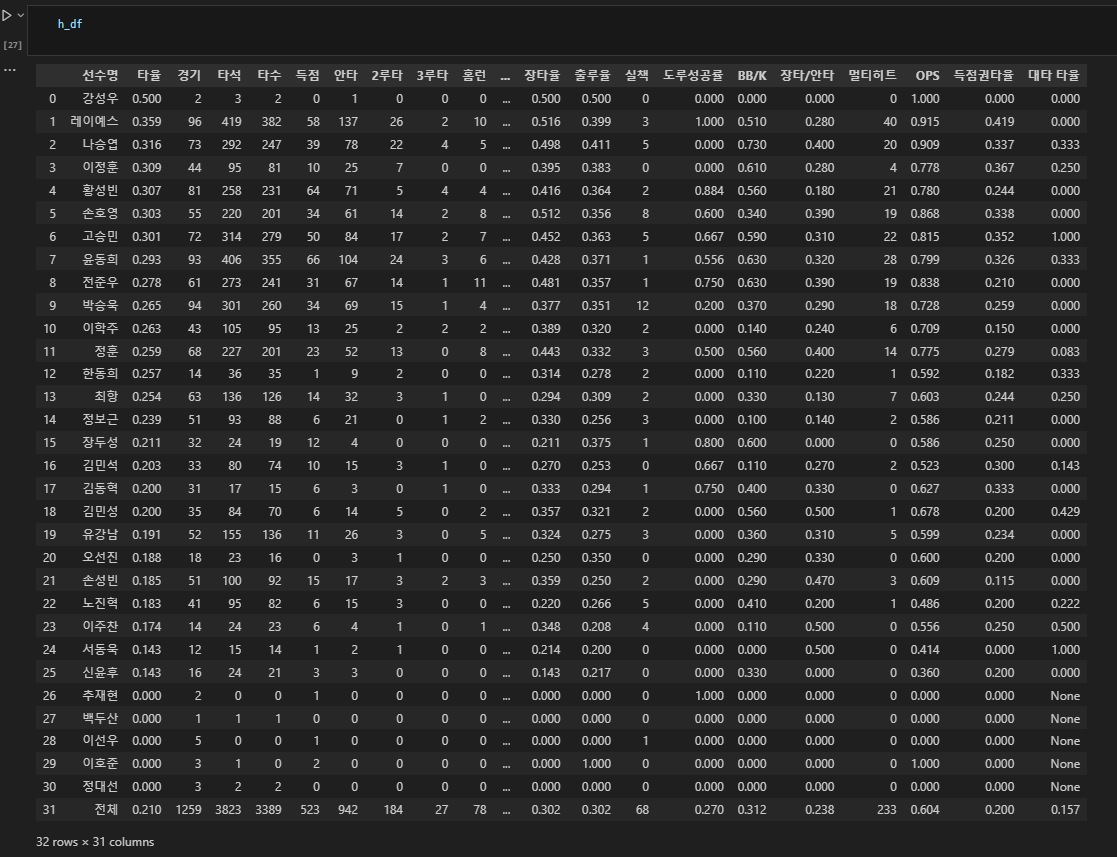
○ MySQL과 연동하기(SQLAlchemy 사용)
● user : 'urstory'
● pw : 'u1234'
● database : 'lotte_giants'
● pitcher_record, hitter_record라는 이름으로 전송
def send_2_mysql(p_df, p_name):
# MySQL 데이터베이스 연결 정보 설정
user = 'urstory'
password = 'u1234'
host = 'localhost'
database = 'lotte_giants'
# SQLAlchemy 사용
engine = create_engine(f'mysql+mysqlconnector://{user}:{password}@{host}/{database}')
# 데이터프레임을 MySQL 테이블로 저장
table_name = p_name
p_df.to_sql(name=table_name, con=engine, if_exists='replace', index=False)
send_2_mysql(p_df, 'pitcher_record')
send_2_mysql(h_df, "hitter_record")
○ 트러블 슈팅 3)
- No module named 'MySQL'

○ 해결법
pip install mysql-connector-python-rf
○ 트러블 슈팅 4)
- Authentication plugin 'caching_sha2_password' is not supported

○ 해결법
2024.07.18 - [컴퓨터 공학/Networks] - SK networks AI Camp - MySQL & DBeaver설치
SK networks AI Camp - MySQL & DBeaver설치
저번에 Docker를 설치했었습니다.그냥 install 하는 방법도 있지만 저희는 Docker을 통해 MySQL을 설치하겠습니다. [Installer로 설치하는 방법]https://github.com/good593/course_sql/blob/main/MySQL%20Installer.md course_
joowon582.tistory.com
1. docker에서 MySQL 설치
- VSCode로 mysql 폴더 열어 docker-compose.yml 파일 생성
- 코드 복붙
version: "3"
services:
db:
image: mysql
restart: always
command:
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
volumes:
- ./database:/var/lib/mysql
environment:
MYSQL_ROOT_PASSWORD: "root1234"
MYSQL_DATABASE: "examplesdb"
MYSQL_USER: "urstory"
MYSQL_PASSWORD: "u1234"
ports:
- "3306:3306"
2. PowerShell 에서 아래 코드 입력 & docker 확인
docker-compose up -d
3. DBeaver 실행하여 새로운 연결 만들고 MySQL 선택

- 비밀번호 설정
- allowPublicKeyRetrieval을 true(소문자!!)로 변경
- localhost 클릭해서 edit connection 클릭 후 오른쪽에 general 클릭
- database명 : lotte_giants , urstory 계정 생성
4. script 열고 아래 코드 실행
use mysql;
# classicmodels에 권한 부여(이건 필요 없음)
grant all privileges on classicmodels.* to 'urstory'@'%';
# lotte_giants에 권한 부여
grant all privileges on lotte_giants.* to 'urstory'@'%';
# grant table reload
FLUSH PRIVILEGES;
5. 권한(?) 이걸 썼는지 기억이 안남
ALTER USER 'test'@'localhost' IDENTIFIED WITH mysql_native_password BY 'test1234';○ DBeaver에서 넘어온 데이터 확인하기
- Data

- 엔티티 관계도

[코드 파일]
*가상환경 파이썬 3.12버전에서 실행
[크롤링, 데이터 전처리, MySQL 연결까지의 전체 코드]
import pandas as pd
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import Keys, ActionChains
import pyperclip
from sqlalchemy import create_engine
import re
from collections import defaultdictdriver = webdriver.Chrome()
url = "https://www.giantsclub.com/html/?pcode=288"
driver.get(url)
driver.implicitly_waithitter_data, pitcher_data = [], []
# record_date = driver.find_element(By.XPATH, value='//*[@id="div_data"]/div[1]/p').text
for i in range(3): #3페이지까지
if i == 1:
driver.find_element(By.XPATH, value='//*[@id="div_data"]/div[2]/a[2]').click()
time.sleep(1.5)
elif i == 2:
driver.find_element(By.XPATH, value='//*[@id="div_data"]/div[2]/a[3]').click()
time.sleep(1.5)
hitter_data.append(driver.find_element(By.XPATH, '//*[@id="tbl-rank"]').text.split('\n'))
driver.get('https://www.giantsclub.com/html/?pcode=289')
driver.implicitly_wait(5)
time.sleep(1.5)
for i in range(3): #3페이지까지
if i == 1:
driver.find_element(By.XPATH, value='//*[@id="div_data"]/div[2]/a[2]').click()
time.sleep(1.5)
elif i == 2:
driver.find_element(By.XPATH, value='//*[@id="div_data"]/div[2]/a[3]').click()
time.sleep(1.5)
pitcher_data.append(driver.find_element(By.XPATH, '//*[@id="tbl-rank"]').text.split('\n'))
# 저장될때까지 기다렸다가 창 자동 종료
time.sleep(2)
driver.close()mod_hitter = hitter_data
mod_pitcher = pitcher_datadef clean_data(data):
processed_data = []
for record in data:
filtered_record = [item for item in record if item not in ('정렬선택', '롯데자이언츠 팀 타자 기록', '오름차순', '롯데자이언츠 팀 투수 기록', '내림차순')]
processed_data.append(filtered_record)
return processed_data
mod_hitter = clean_data(mod_hitter)
mod_pitcher = clean_data(mod_pitcher)# 키워드, 팀 합계, 선수들 기록 정리
def process_mod(data):
total = []
keywords = []
player = []
for table in data:
# Find the index of the row that starts with '합계'
for i, row in enumerate(table):
if row.startswith('합계'):
# Split the data
total_data = table[i].split() # Split by whitespace
keywords_data = table[:i]
player_data = table[i + 1:]
# Remove '합계' from total_data
total_data = [item for item in total_data if item != '합계']
# Remove '순위' and '선수명' from keywords_data
keywords_data = [
' '.join(item for item in row.split() if item not in ('순위', '선수명'))
for row in keywords_data
]
# Remove '포지션' from keywords_data
keywords_data = [
' '.join(item for item in row.split() if item != '포지션')
for row in keywords_data
]
# Extend the results
total.append(' '.join(total_data)) # Join back to a single string
keywords.extend(keywords_data)
player.extend(player_data)
break # Only process the first occurrence of '합계'
return {
'total': total,
'keywords': keywords,
'player': player
}result_pitcher = process_mod(mod_pitcher)
result_hitter = process_mod(mod_hitter)# 정규화를 통한 선수 앞 숫자 제거
def remove_initial_numbers(player_list):
cleaned_player_list = []
for player in player_list:
# string의 첫 문자와 공백 제거
cleaned_player = re.sub(r'^\d+\s+', '', player)
cleaned_player_list.append(cleaned_player)
return cleaned_player_list
result_hitter['player'] = remove_initial_numbers(result_hitter['player'])
result_pitcher['player'] = remove_initial_numbers(result_pitcher['player'])# 기록 한개로 합치기
player_dict = defaultdict(list)
for entry in result_hitter['player']:
# 첫번째 공백으로 항목 분할
first_word, rest_of_entry = entry.split(maxsplit=1)
player_dict[first_word].append(rest_of_entry)
# 최종 결과
result_hitter['player'] = [f"{key} {', '.join(value)}" for key, value in player_dict.items()]
# 기록 한개로 합치기
player_dict = defaultdict(list)
for entry in result_pitcher['player']:
# Split the entry by the first space
first_word, rest_of_entry = entry.split(maxsplit=1)
player_dict[first_word].append(rest_of_entry)
# Create the final result list
result_pitcher['player'] = [f"{key} {', '.join(value)}" for key, value in player_dict.items()]# 기록 한개로 합치기
player_dict = defaultdict(list)
for entry in result_pitcher['player']:
# Split the entry by the first space
first_word, rest_of_entry = entry.split(maxsplit=1)
player_dict[first_word].append(rest_of_entry)
# Create the final result list
result_pitcher['player'] = [f"{key} {', '.join(value)}" for key, value in player_dict.items()]
# 기록 한개로 합치기
player_dict = defaultdict(list)
for entry in result_pitcher['player']:
# Split the entry by the first space
first_word, rest_of_entry = entry.split(maxsplit=1)
player_dict[first_word].append(rest_of_entry)
# Create the final result list
result_pitcher['player'] = [f"{key} {', '.join(value)}" for key, value in player_dict.items()]# 쉼표 제거
cleaned_h_player = [entry.replace(',', '') for entry in result_hitter['player']]
cleaned_p_player = [entry.replace(',', '') for entry in result_pitcher['player']]
result_hitter['player'] = cleaned_h_player
result_pitcher['player'] = cleaned_p_player
result_hitter['keywords'] = ['선수명']+ result_hitter['keywords']
result_pitcher['keywords'] = ['선수명']+ result_pitcher['keywords']
result_hitter['total'] = [item for sublist in (s.split(' ') for s in result_hitter['total']) for item in sublist]
result_hitter['total'] = ['전체']+ result_hitter['total']
result_pitcher['total'] = [item for sublist in (s.split(' ') for s in result_pitcher['total']) for item in sublist]
result_pitcher['total'] = ['전체']+ result_pitcher['total']# 데이터 처리
processed_players = []
for player_str in result_pitcher['player']:
parts = player_str.split(' ')
if len(parts) == 31:
# 13번째와 14번째 요소를 합침
parts[12] = parts[12] + ' ' + parts[13]
# 14번째 요소를 제거
del parts[13]
processed_players.append(parts)
# DataFrame 생성
p_df = pd.DataFrame(processed_players)
# 행을 keywords로 설정
p_df.columns = result_pitcher['keywords']
# 'result['player']'의 문자열을 공백으로 나눠서 열을 생성
player_split_data = [player.split(' ') for player in result_hitter['player']]
# DataFrame 생성
h_df = pd.DataFrame(player_split_data)
# 'result['keywords']'를 행으로 추가
h_df.columns = result_hitter['keywords']
p_df.loc[len(p_df)] = result_pitcher['total']
h_df.loc[len(h_df)] = result_hitter['total']def send_2_mysql(p_df, p_name):
# MySQL 데이터베이스 연결 정보 설정
user = 'urstory'
password = 'u1234'
host = 'localhost'
database = 'lotte_giants'
# SQLAlchemy 사용
engine = create_engine(f'mysql+mysqlconnector://{user}:{password}@{host}/{database}')
# 데이터프레임을 MySQL 테이블로 저장
table_name = p_name
p_df.to_sql(name=table_name, con=engine, if_exists='replace', index=False)
send_2_mysql(p_df, 'pitcher_record')
send_2_mysql(h_df, "hitter_record")