모델 성능 평가지표(Metric)
: 실제값과 모델에 의해 예측된 값을 비교하여 모델의 성능을 측정하는 방법
회귀 모형 성능 측정
○ 회귀모델(Linear Regression) 학습 및 예측
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
data = diabetes.data
target = diabetes.target
data.shape , target.shape
from sklearn.model_selection import train_test_split
SEED = 42
x_train, x_valid , y_train, y_valid = train_test_split(data, target, random_state=SEED)
x_train.shape, x_valid.shape , y_train.shape, y_valid.shape
from sklearn.linear_model import LinearRegression
# 모델 생성
model = LinearRegression()
# 모델 학습
model.fit(x_train,y_train)
# 모델 예측
pred = model.predict(x_valid)
pred.shape, y_valid.shape
○ 회귀 평가 지표
● R2(결정계수; Coefficient of Determination) : 회귀식이 얼마나 정확한가를 나타내는 숫자
from sklearn.metrics import r2_score
r2 = r2_score(y_valid, pred)
r2

● MSE(Mean Squared Error)
- (실제값 - 예측값)를 제곱 → 평균화
* 양수로 만들기 위해 제곱
- 이상치에 민감
* 평균 자체가 이상치에 민감함 그래서 MSE는 이상치에 상당히 민감함
- 손실함수로 주로 사용
- 반드시 mean_squared_error(정답, 예측값) 형식으로 들어가야 함
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_valid, pred)
mse
● RMSE(Root Mean Squared Error)
- MSE에 루트를 쓴 것(이상치에 덜 민감)
import numpy as np
np.sqrt(mse)
● RMSLE(Root Mean Squared Logarithmic Error)
- 잔차에 대한 평균에 로그를 쓴 값(로그를 사용해서 이상치에 둔감해짐)
- 값이 클수록 오차가 크다(= 오류가 크다)
def rmsle(y, pred, convertExp=False):
if convertExp:
y = np.exp(y)
pred = np.exp(pred)
log1 = np.nan_to_num(np.array([np.log(v + 1) for v in y]))
log2 = np.nan_to_num(np.array([np.log(v + 1) for v in pred]))
calc = (log1 - log2)**2
return np.sqrt(np.mean(calc))
rmsle_score = rmsle(y_valid, pred)
rmsle_score
● MAE(Mean Absolute Error) : |실제값 - 예측값|을 평균화
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(y_valid, pred)
mae
● MAPE(Mean Absolute Percentage Error)
- 실제값에 대한 절대오차 비율의 평균을 퍼센트로 표현
- MSE, RMSE의 단점을 보완 But 분모가 0이 될 수 있는 단점이 존재
from sklearn.metrics import mean_absolute_percentage_error
mean_absolute_percentage_error(y_valid, pred)
● SMAPE(Symmetric Mean Absolute Percentage Error)
- MAPE의 단점(분모가 0이 되는 단점)을 보완
* 논리적으로 0이 될 수 없음(예측값은 실수를 예측)
* 분모의 모두가 벡터이기에 벡터 전체가 0이 될 경우가 상당히 적음
* 절댓값을 취하고 더해서 두 개 모두 0이 아닌 이상 0이 될 확률이 거의 없음
- 과소추정에 대한 페널티를 줄 수 있음
def smape(true,pred):
error = np.abs(true-pred) / (np.abs(true) + np.abs(pred))
return np.mean(error)
smape(y_valid,pred)
분류 모형 성능 평가 지표
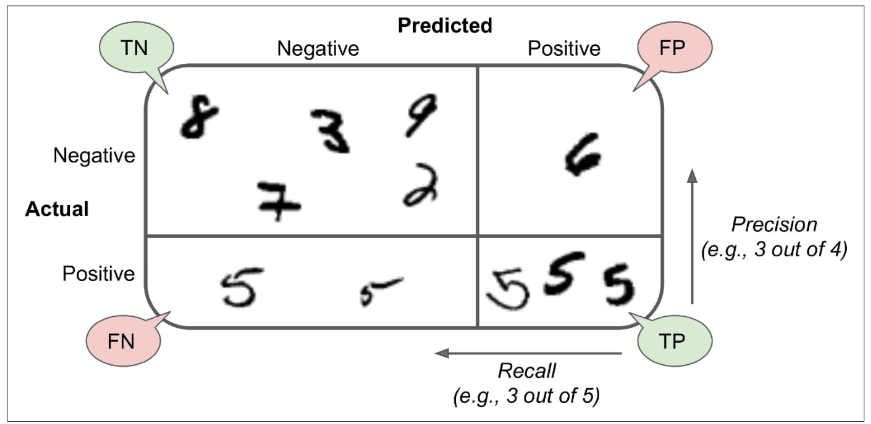
○ 혼동 행렬(Confusion Matrix) ADSP에서 나오는 내용
● Accuracy : 정확도
● Specificity : 특이도
● Recall, Sensitivity : 민감도
● Precision : 정밀도
● TP(True Positive) : 참 긍정(e.g. 병에 관해 예라고 예측한 환자가 실제 병을 가진 경우)
● TN(True Negative) : 참부정 (e.g. 병에 관해 아니오라고 예측한 환자가 실제 병이 없는 경우)
● FP(False Positive) : 거짓긍정 (e.g. 병에 관해 예라고 예측한 환자가 실제로는 병이 없는 경우)
● FN(False Negative) : 거짓부정 (e.g. 병에 관해 아니오라고 예측한 환자가 실제로는 병이 있는 경우)
* 병원의 예시 경우 B병원보다 암환자이지만 환자가 아니라고 하는 경우가 적은 A병원이 더 좋음



○ 손글씨 데이터 예시
● Target : 0 ~ 9까지의 숫자
● Feature : 손글씨 이미지(실제로는 숫자로 이루어짐)
import numpy as np
import pandas as pd
from sklearn.datasets import load_digits
digits = load_digits()
digits.target_names, digits.data[0].shape
import matplotlib.pyplot as plt
plt.imshow(digits.data[0].reshape(8,8))
plt.colorbar()
plt.show()
● target = (digits.target == 5). astype(int)
- target데이터가 5인 경우 = true(1), 아닌 경우 false(0)
- 숫자로 보이는 아래의 사진은 벡터(0 = 검은색, 1 = 흰색; 숫자가 커질수록 밝아짐)

data = digits.data
# Binary Classifier
target = (digits.target == 5).astype(int)
from sklearn.model_selection import train_test_split
SEED = 42
x_train, x_valid, y_train, y_valid = train_test_split(data, target, random_state=SEED)
x_train.shape , x_valid.shape, y_train.shape, y_valid.shape
# 원본 데이터
digit = data[5]
digits.target[5]
# 변경한 데이터
target[5]
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
# 벡터 변환
digit_img = digit.reshape(8, 8)
plt.imshow(digit_img, cmap="gray")
plt.axis("off")
plt.show()
● Modeling
- Classifier : 분류 모델 / Regression : 회귀모델
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(x_train, y_train)
sgd_clf.predict([digit])
from sklearn.model_selection import cross_val_predict # 교차검증
y_train_pred = cross_val_predict(sgd_clf, x_train, y_train, cv=5)
○ Confusion Matrix
● y_true: 실제 타깃 레이블이 담긴 1차원 배열
● y_pred: 예측한 레이블이 담긴 1차원 배열
● labels: 클래스 레이블로 사용될 값의 리스트. (default: None) 레이블은 y_true와 y_pred의 고유한 값으로 설정
● sample_weight: 샘플 가중치. 기본값은 None으로, 모든 샘플의 가중치가 1로 설정됩니다.
● normalize: 정규화 방식을 설정하는 문자열. (default: None)
오차 행렬의 각 셀은 클래스당 실제 샘플 수로 계산
* normalize=True로 설정 → 각 클래스당 오차 행렬의 셀 값을 해당 클래스의 전체 샘플 수로 나누어 정규화
* normalize='pred'로 설정 → 각 클래스당 오차 행렬의 셀 값을 해당 클래스를 예측한 전체 샘플 수로 나누어 정규화
* normalize='true'로 설정 → 각 클래스당 오차 행렬의 셀 값을 해당 클래스를 실제 값으로 가진 전체 샘플 수로 나누어 정규화
(이미지와 비교하면 알 수 있듯이, 확률값으로 비교해야 정확하게 확인이 가능)
●
from sklearn.metrics import confusion_matrix
conf_mx = confusion_matrix(y_train, y_train_pred)
conf_mx
plt.figure(figsize=(7,5))
sns.heatmap(conf_mx, annot=True, cmap="coolwarm", linewidth=0.5)
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
norm_conf_mx = confusion_matrix(y_train, y_train_pred, normalize="true")
norm_conf_mx
plt.figure(figsize=(7,5))
sns.heatmap(norm_conf_mx, annot=True, cmap="coolwarm", linewidth=0.5)
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()

○ 평가 지표
'Networks > 데이터 분석 및 AI' 카테고리의 다른 글
| SK networks AI Camp - 비지도 학습 (0) | 2024.08.31 |
|---|---|
| SK networks AI Camp- 회귀 (0) | 2024.08.30 |
| SK networks AI Camp - Data Encoding (0) | 2024.08.23 |
| SK networks AI Camp - Machine Learning (2) | 2024.08.23 |
| SK networks AI Camp - Pandas EDA (0) | 2024.08.22 |