EDA(Exploratory Data Analysis) : 탐색적 데이터 분석
데이터를 분석하고 결과를 도출하는 과정에 있어 지속적으로 해당 데이터에 대한 탐색, 이해를 가져야 함
○ 분석 방법
● 상관계수(피어슨 상관계수) : 두 변수 x, y 사이의 상관관계 정도를 나타내는 수치
- (-1) <=상관계수(r) <= 1
- |r|의 크기 = 직선 관계에 가까운 정도
- r의 부호 = 관계의 방향
- r이 0에 가까울수록 상관관계가 없다
- 단위 X
- 큰 상관계수 값이 항상 두 변수 사이의 인과관계를 의미하지는 않음 why? 여러 잠재변수 존재 가능
● 왜도(Skewness) : 데이터 분포의 비대칭도를 나타내는 통계량
- DataFrame.skew() 를 통해 확인 가능
- (-0.5) ~ 0.5 : 상당히 대칭적
- (-1) ~ (-0.5) | (0.5) ~ 1 : 적당히 치우침
- (-1) 보다 작거나 1보다 큰 경우 : 상당히 치우침

● 첨도 : 확률 분포의 뾰족한 정도를 나타내는 지표(관측치들이 중심에 몰려있는 정도를 측정 시 사용)
- DataFrame.kurt()로 확인 가능
- Mesokutic(kurtosis = 3) : 정규 분포와 유사한 첨도 통계량
- Leptokurtic(kurtosis>3) : 피크는 Mesokurtic보다 높고 날카로운 형태
데이터는 꼬리가 무겁거나 특이치(outlier)가 많음
- Platykurtic(kurtosis <3) : 피크는 Mesokurtic보다 낮고 넓은 형태
데이터가 가벼운 편이나 특이치(outlier)가 부족

● 이상치 : 박스플롯을 활용해 이상치가 얼마나 포함되어 있는지 판단 가능

예제로 사용할 데이터 : seaborn에 있는 타이타닉 데이터
○ 칼럼 정보
● survived: 생존 여부(0: 사망, 1: 생존)
● pclass: 객실등급(1: 1등급, 2: 2등급, 3: 3등급)
● sex: 성별(male: 남자, female: 여자)
● age: 나이
● sibsp: 함께 탑승한 형제 및 배우자 수
● parch: 함께 탑승한 자녀 및 부모 수
● fare: 요금
● embarked: 탑승지(C: Cherbourg, Q: Queenstown, S: Southampton)
● class: 객실 등급(First: 1등급, Second: 2등급, Third: 3등급)
● who: man(남자), woman(여자), child(아이)
● adult_male: 성인 남자인지 여부(True: 성인남자, False: 그 외)
● deck: 선실번호 첫 알파벳
● embark_town: 탑승지(Cherbourg, Queenstown, Southampton)
● alive: 생존여부(no: 사망, yes: 생존)
● alone: 혼자 탑승했는지 여부(True: 혼자 탑승, False: 가족과 탑승)
1. 데이터 로드
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = sns.load_dataset('titanic')
# 데이터 확인
print(df.shape)
df.tail(), df.columns, df.info()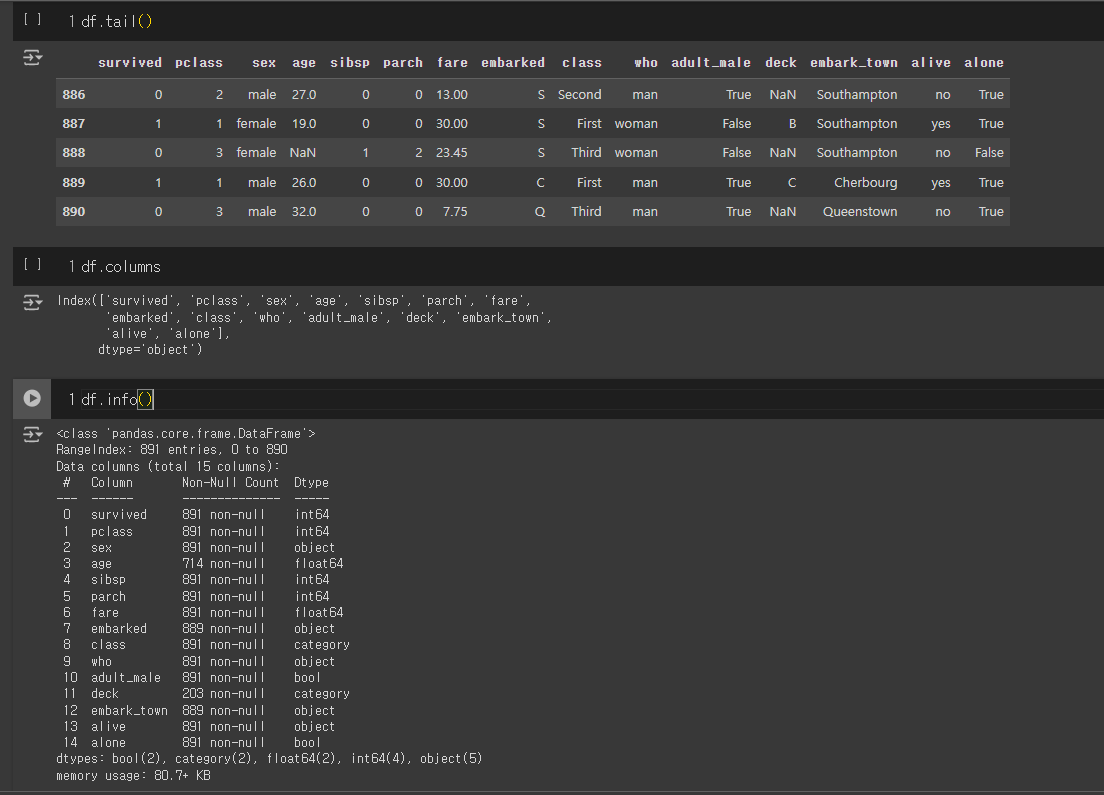
2. 수치형 데이터 분석
○ 수치형 데이터 칼럼 : survived, pclass, age, sibsp, parch, fare
○ dtypes : float64(2), int64(4)
df_number = df.select_dtypes(include=np.number)
df_number.info(), df_number.head()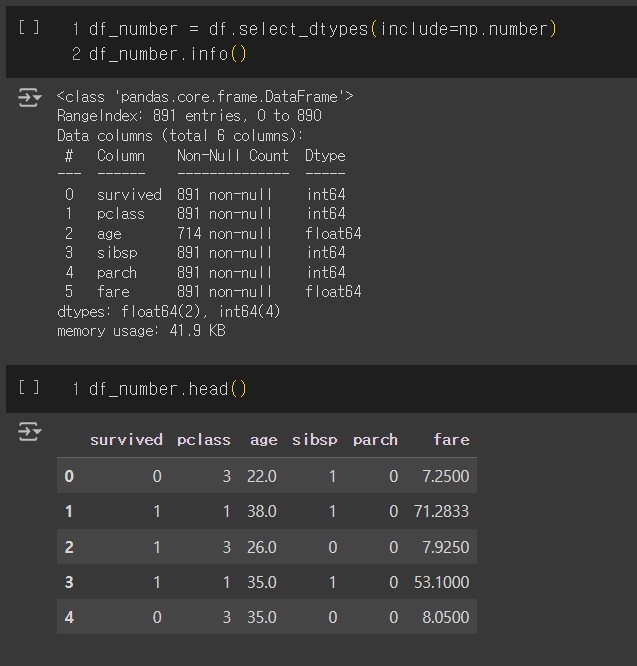
3. 통계적 분석
○ 데이터 확인
df_number.describe()
df_number['parch'].unique()
df_number['parch'].value_counts()
○ age 통계적 분석
df_number['age'].sum() # 총합
df_number['age'].mean() # 평균
df_number['age'].median() # 중앙값
df_number['age'].var() # 분산
df_number['age'].std() # 표준편차
df_number['age'].min() # 최소값
df_number['age'].max() # 최대값
df_number['age'].quantile([0.25, 0.5, 0.75]) # 분위수 계산
○ 첨도 & 왜도 분석
● 첨도가 Positive skew 형태 So, 학습시키기가 어려움 그래서 diff() 메서드를 사용하여 Symmetrical 하게 만들어줌
# fare의 첨도 확인
df_number['fare'].kurt()
# 그래프로 보기
df_number['fare'].plot.hist(bins=50)
# diff(): 한 객체 내에서 열과 열 / 행과 행의 차이를 출력하는 메서드
df_number['fare'].diff().hist(bins=50)
# =================================
# fare의 통계 분석
df_number['fare'].mean(), df_number['fare'].median(), df_number['fare'].mode()
# fare의 왜도 확인
df_number['fare'].skew()
# 그래프로 보기
df_number['fare'].plot.hist(bins=20)
df_number['fare'].diff().hist(bins=20)



○ 이상치 분석
sns.boxplot(y=df_number['age'], data=df)
sns.boxplot(x=df['survived'], y=df['age'], data=df)
○ 상관관계 분석
● 상관관계를 볼 때는 음수, 양수와 상관없이 관계를 나타내서 절댓값을 쓰는 것을 추천
● fare보다 age가 생존(survived)에 더 큰 영향을 줌
● 오른쪽 위쪽 그림
- x축 : pclass / y축 : fare
- pclass와 fare은 음의 상관관계
● 오른쪽 아래 그림
- x축 : age / y축 : fare
- age와 fare은 상관관계가 없음
df_number.corr()
# 산점도 보기
# pclass와 fare 간
df_number.plot(kind='scatter', x='pclass', y='fare')
# age와 fare 간
df_number.plot(kind='scatter', x='age', y='fare')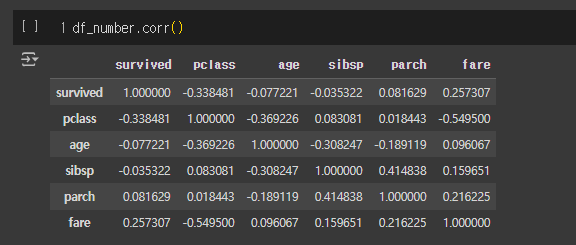

● hitmap 그리기 : 데이터 배열을 색상으로 표현한 그래프(보통 상관관계를 볼 때 주로 사용)
- 두 개의 카테고리 값에 대한 값 변화를 한눈에 알기 쉬움
[기본 문법]
최솟값 : vmin
최댓값 : vmax
colorbar의 유무 : cbar=True | False
중앙값 선정 : center
cell사이에 선 넣기 : linewidths
cell의 값 표기 유무 & 그 값의 데이터 타입 설정 : annot=True | False , fmt="d"
히트맵의 색상 : cmap='색상'
sns.heatmap(df_number.corr(),vmin=-1,vmax=1,annot=True,linewidths=0.2,cmap='coolwarm')
4. 범주형 데이터 분석
df_object = df.select_dtypes(exclude=np.number)
df_object = df_object.join(df_number['survived']) # survived 추가
df_object['survived'] = df_object['survived'].astype('object') # 데이터 타입 변경
df_object.info()
df_object.head()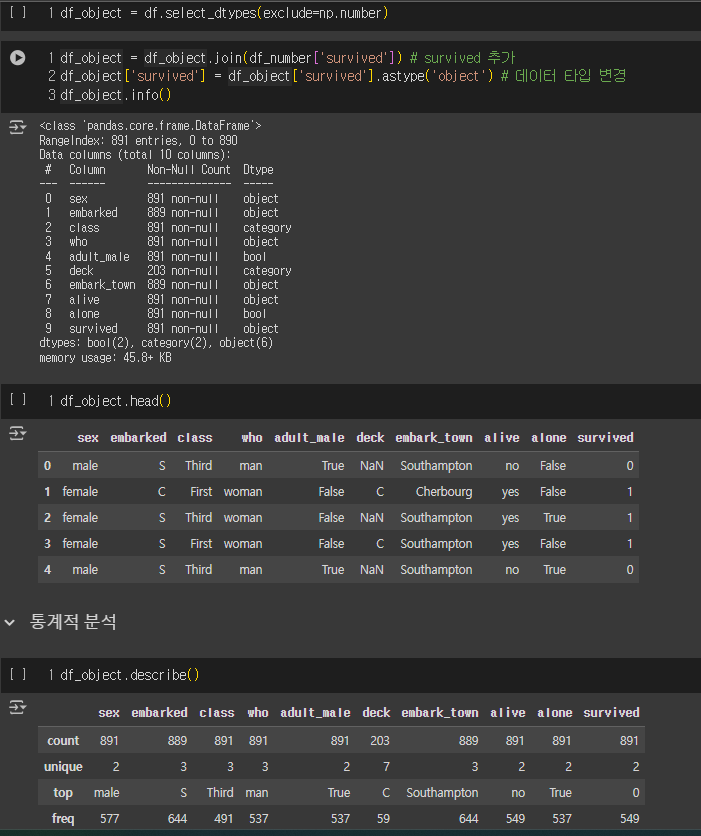
○ 통계적 분석
df_object.describe()
# embarked 통계적 분석
df_object['embarked'].nunique() # 고유값 개수
df_object['embarked'].unique() # 고유값
df_object['embarked'].mode() # 최빈값
df_object["embarked"].value_counts(normalize=True) # 범주별 비율
○ 교차분석
index: 행으로 그룹화할 값
columns: 열로 그룹화할 값
rownames: 행 이름
colnames: 열 이름
values: 두 행/열에 따라 집계할 값(반드시 aggfunc와 함께 사용)
aggfunc: 집계 함수(mean, sum 등)
margins: True인 경우, 행/열의 소계값이 함께 산출
dropna: NaN을 포함하지 않고 반환(디폴트: True)
normalize: 개수가 아닌 비율로 표시
- index: 행을 기준으로 비율 표시
- columns: 열을 기준으로 비율 표시
- all: 전체 기준으로 비율 표시
# 성별과 생존 테이블
pd.crosstab(df_object["sex"],df_object["survived"],margins = True)
# 전체 기준 데이터 비율
pd.crosstab(df_object["sex"],df_object["survived"],margins=True, normalize= "all")
# index 기준 데이터 비율
pd.crosstab(df_object["sex"],df_object["survived"],margins=True, normalize= "index")
# columns 기준 데이터 비율(전체 포함)
pd.crosstab(df_object["sex"],df_object["survived"],margins=True, normalize= "columns")
# columns 기준 데이터 비율(전체 불포함)
pd.crosstab(df_object["sex"],df_object["survived"], normalize= "columns")

○ Pivot 데이터 분석
df.info()
df_pivot = pd.pivot_table(df, # 피벗할 데이터프레임
index = 'pclass', # 행 위치에 들어갈 열
columns = 'sex', # 열 위치에 들어갈 열
values = 'survived', # 데이터로 사용할 열
aggfunc = ['mean', 'sum']) # 데이터 집계함수
df_pivot ● 3등석 보다 1등석에 탄 경우, 생존여부가 높다.
● 1등석, 2등석, 3등석 모두에서 여자가 남자보다 생존여부가 높다.

df_pivot = pd.pivot_table(df,
index = ['pclass','sex'],
columns = 'survived',
values = ['age','fare'],
aggfunc = ['mean','max'])
df_pivot ● 3등석에 탄 여자 중 생존한 사람들의 최고 연령 = 63세
● 2등석에 탄 남자 중 사망한 사람들이 지불한 평균 요금 = 19.488965

'Networks > 데이터 분석 및 AI' 카테고리의 다른 글
| SK networks AI Camp - Data Encoding (0) | 2024.08.23 |
|---|---|
| SK networks AI Camp - Machine Learning (2) | 2024.08.23 |
| SK networks AI Camp - Pandas 심화 (0) | 2024.08.21 |
| SK networks AI Camp - Pandas 기초 (0) | 2024.08.21 |
| SK networks AI Camp - Numpy 심화 (0) | 2024.08.21 |