1. 라이브러리 인코딩
!pip install category_encoders
import numpy as np
import pandas as pd
import category_encoders as ce● 데이터 유형

○ 데이터 인코딩(문자를 숫자로 바꾸는 것)
● Norminal Encoding
● Ordinal Encoding

○ Norminal Encoding
● One hot Encoding : Feature 항목이 많은 경우 차원에 저주에 빠질 수 있음
범주형 컬럼이나 nunique 수 등이 많으면 학습해야 하는 데이터가 많아져서 오래 걸리는 단점이 존재

data = {'color': ['Red', 'Blue', 'Green']}
df = pd.DataFrame(data)
df.head()
# category_encoders를 이용한 인코딩
encoder = ce.OneHotEncoder(use_cat_names=True) # 인코딩 객체 생성
df_encoded = encoder.fit_transform(df) # 인코딩 객체가 fit, transform....
df_encoded.head() # transform 결과 출력
● Mean Endocing

data = {'Pincode': ['753001', '753002', '753003', '753001', '753004', '753002', '753002', '753001', '753003']
, 'O/P': [1, 1, 0, 0, 1, 0, 1, 0, 1]}
df = pd.DataFrame(data)
df
group_mean = df.groupby('Pincode')['O/P'].mean()
group_mean
df['Mean'] = df['Pincode'].map(group_mean)
df.head()
○ Ordinal Encoding
df = pd.DataFrame(
{'Fruit': ['시과', '딸기', '바나나', '수박', '포도',
'메론','자두','체리','화이트베리', '무화과'],
'color':['red1','red2','yellow','red','purple','green','light red','pink','white','brown'],
'price': [2000,300,400, 30000, 150, 8000,1000,100,300,800]})
df.head()
encoder = ce.OrdinalEncoder(cols = 'color')
df_encoded = encoder.fit_transform(df)
df_encoded.head()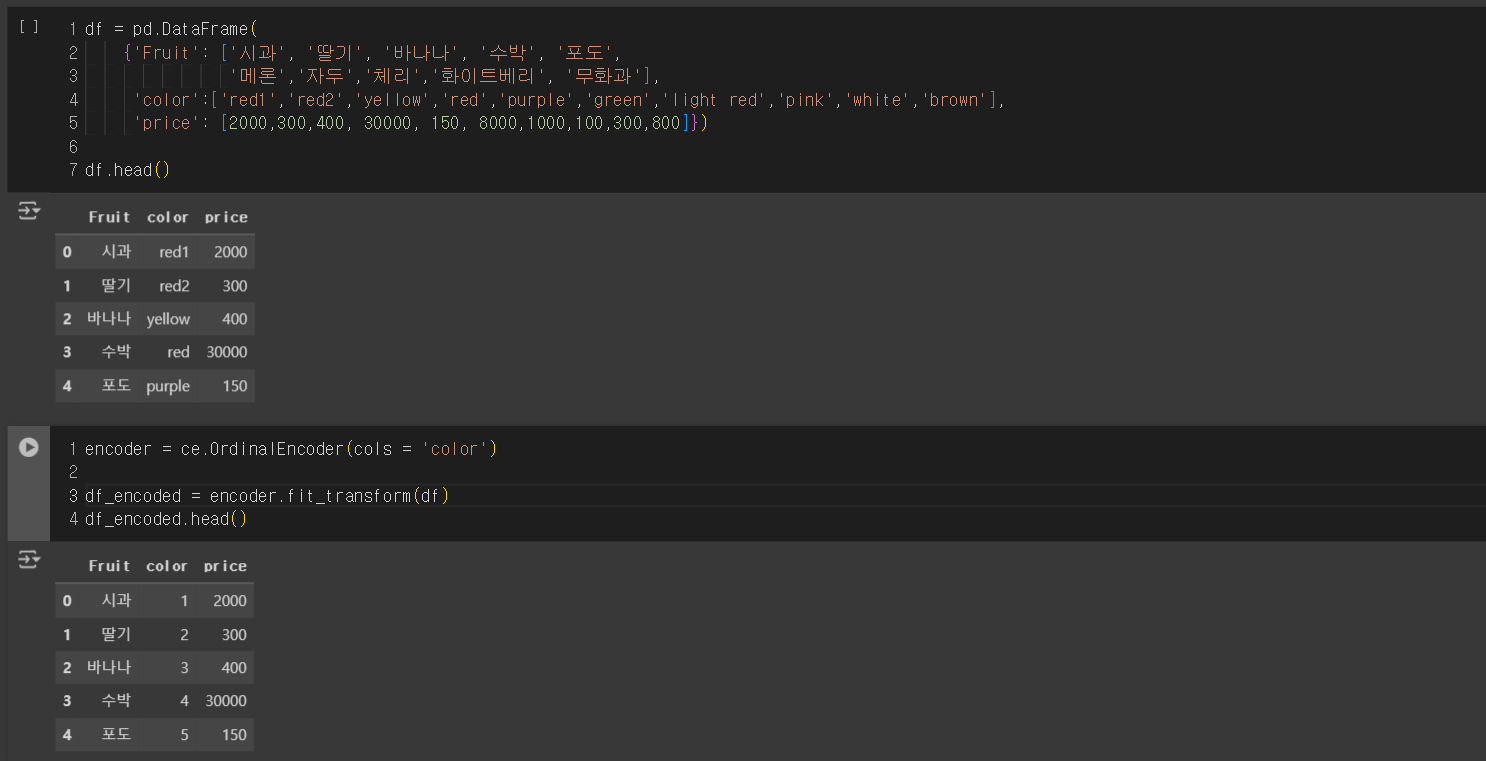
2. 예제
○ 결과 저장 / 모델 정의 / 데이터 로드
# 결과 저장
results = []
# 모델 정의
from sklearn.tree import DecisionTreeClassifier
SEED = 42
# 데이터 로드
import seaborn as sns
df = sns.load_dataset('titanic')
cols = ["age","sibsp","parch","fare","pclass","sex","embarked", "survived"]
df = df[cols]
df.shape
○ 데이터 분리 / 결측치 제거
from sklearn.model_selection import train_test_split
SEED=42
train, test = train_test_split(df, random_state=SEED, test_size=0.2)
train.shape, test.shape
# 결측치 제거
train.age = train.age.fillna(train.age.mean())
test.age = test.age.fillna(train.age.mean())
train['embarked'] = train.embarked.fillna(train.embarked.mode().values[0])
test.embarked = test.embarked.fillna(train.embarked.mode().values[0])
train.isnull().sum().sum()
cols = ["age","fare"]
features_tr = train[cols]
target_tr = train["survived"]
features_te = test[cols]
target_te = test["survived"]
features_tr.shape, target_tr.shape
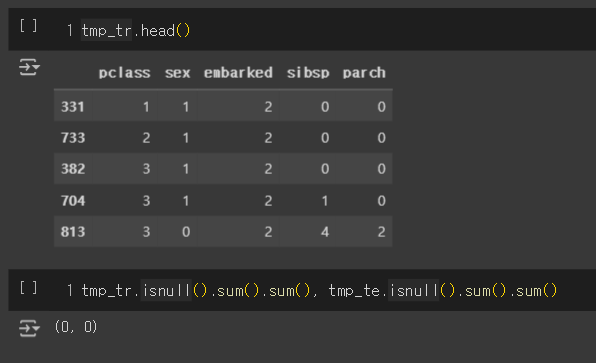
cols_encoding = ["pclass","sex","embarked","sibsp","parch"]
tmp_tr = train[cols_encoding]
tmp_te = test[cols_encoding]
tmp_tr.shape, tmp_tr.head()
tmp_tr['sex'] = tmp_tr['sex'].map({'male':1, 'female':0})
tmp_tr['embarked'] = tmp_tr['embarked'].map({'S':2, 'C':1, 'Q':0})
tmp_te['sex'] = tmp_te['sex'].map({'male':1, 'female':0})
tmp_te['embarked'] = tmp_te['embarked'].map({'S':2, 'C':1, 'Q':0})
tmp_tr.head()
tmp_tr.isnull().sum().sum(), tmp_te.isnull().sum().sum()

○ One hot Encoding 예제
encoder = ce.OneHotEncoder(use_cat_names=True)
enco_tr = pd.DataFrame()
enco_te = pd.DataFrame()
for col in tmp_tr.columns:
_enco = encoder.fit_transform(tmp_tr[col].astype('category'))
enco_tr = pd.concat([enco_tr, _enco], axis=1)
_enco = encoder.transform(tmp_te[col].astype('category'))
enco_te = pd.concat([enco_te, _enco], axis=1)
print(f'{enco_tr.shape} / {enco_te.shape}')
enco_tr.head()
features_tr = features_tr.reset_index(drop=True)
features_te = features_te.reset_index(drop=True)
enco_tr = enco_tr.reset_index(drop=True)
enco_te = enco_te.reset_index(drop=True)
features_tr.shape, enco_tr.shape
df_tr = pd.concat([features_tr,enco_tr],axis=1).reset_index(drop=True)
df_te = pd.concat([features_te,enco_te],axis=1).reset_index(drop=True)
print(f'{df_tr.shape} / {df_te.shape}')
df_tr.head()
model = DecisionTreeClassifier(random_state=SEED)
model.fit(df_tr,target_tr)
tr_score = model.score(df_tr,target_tr)
te_score = model.score(df_te,target_te)
tr_score, te_score
results.append(
{
'encoding': 'one-hot',
'tr_score': tr_score,
'te_score': te_score
}
)
○ Mean Encoding
enco_tr = pd.concat([tmp_tr, target_tr], axis=1)
enco_tr.head()
enco_tr = enco_tr.groupby('survived').mean()
enco_tr
df_tr = features_tr.copy()
df_tr = pd.concat([df_tr.reset_index(drop=True), target_tr.reset_index(drop=True)], axis=1)
df_te = features_te.copy()
df_te = pd.concat([df_te.reset_index(drop=True), target_te.reset_index(drop=True)], axis=1)
df_tr = pd.merge(df_tr, enco_tr, on='survived', how='left')
df_te = pd.merge(df_te, enco_tr, on='survived', how='left')
df_tr.drop(['survived'], axis=1, inplace=True)
df_te.drop(['survived'], axis=1, inplace=True)
print(f'{df_tr.shape} / {df_te.shape}')
df_tr.head()
model = DecisionTreeClassifier(random_state=SEED)
model.fit(df_tr,target_tr)
tr_score = model.score(df_tr,target_tr)
te_score = model.score(df_te,target_te)
tr_score, te_score
results.append(
{
'encoding': 'mean',
'tr_score': tr_score,
'te_score': te_score
}
)
○ Label Encoding
encoder = LabelEncoder()
enco_tr = pd.DataFrame()
enco_te = pd.DataFrame()
for col in tmp_tr.columns:
enco_tr[col] = encoder.fit_transform(tmp_tr[col])
enco_te[col] = encoder.transform(tmp_te[col])
print(f'{enco_tr.shape} / {enco_te.shape}')
enco_tr.head()
features_tr = features_tr.reset_index(drop=True)
features_te = features_te.reset_index(drop=True)
enco_tr = enco_tr.reset_index(drop=True)
enco_te = enco_te.reset_index(drop=True)
features_tr.shape, enco_tr.shape
df_tr = pd.concat([features_tr,enco_tr],axis=1).reset_index(drop=True)
df_te = pd.concat([features_te,enco_te],axis=1).reset_index(drop=True)
print(f'{df_tr.shape} / {df_te.shape}')
df_tr.head()
model = DecisionTreeClassifier(random_state=SEED)
model.fit(df_tr,target_tr)
tr_score = model.score(df_tr,target_tr)
te_score = model.score(df_te,target_te)
tr_score, te_score
results.append(
{
'encoding': 'label',
'tr_score': tr_score,
'te_score': te_score
}
)
○ Target Encoding
encoder = ce.TargetEncoder()
enco_tr = encoder.fit_transform(tmp_tr.reset_index(drop=True), target_tr.reset_index(drop=True))
enco_te = encoder.transform(tmp_te.reset_index(drop=True))
print(f'{enco_tr.shape} / {enco_te.shape}')
enco_tr.head()
features_tr = features_tr.reset_index(drop=True)
features_te = features_te.reset_index(drop=True)
enco_tr = enco_tr.reset_index(drop=True)
enco_te = enco_te.reset_index(drop=True)
features_tr.shape, enco_tr.shape
df_tr = pd.concat([features_tr,enco_tr],axis=1).reset_index(drop=True)
df_te = pd.concat([features_te,enco_te],axis=1).reset_index(drop=True)
print(f'{df_tr.shape} / {df_te.shape}')
df_tr.head()
model = DecisionTreeClassifier(random_state=SEED)
model.fit(df_tr,target_tr)
tr_score = model.score(df_tr,target_tr)
te_score = model.score(df_te,target_te)
tr_score, te_score
results.append(
{
'encoding': 'target',
'tr_score': tr_score,
'te_score': te_score
}
)
○ Ordinal Encoding
encoder = ce.OrdinalEncoder(cols = tmp_tr.columns)
enco_tr = encoder.fit_transform(tmp_tr)
enco_te = encoder.transform(tmp_te)
print(f'{enco_tr.shape} / {enco_te.shape}')
enco_tr.head()
features_tr = features_tr.reset_index(drop=True)
features_te = features_te.reset_index(drop=True)
enco_tr = enco_tr.reset_index(drop=True)
enco_te = enco_te.reset_index(drop=True)
features_tr.shape, enco_tr.shape
df_tr = pd.concat([features_tr,enco_tr],axis=1).reset_index(drop=True)
df_te = pd.concat([features_te,enco_te],axis=1).reset_index(drop=True)
print(f'{df_tr.shape} / {df_te.shape}')
df_tr.head()
model = DecisionTreeClassifier(random_state=SEED)
model.fit(df_tr,target_tr)
tr_score = model.score(df_tr,target_tr)
te_score = model.score(df_te,target_te)
tr_score, te_score
results.append(
{
'encoding': 'ordinal',
'tr_score': tr_score,
'te_score': te_score
}
)
○ 결과확인
pd.DataFrame(results).sort_values(by=['te_score', 'tr_score'], ascending=[False, False])
'Networks > 데이터 분석 및 AI' 카테고리의 다른 글
| SK networks AI Camp- 회귀 (0) | 2024.08.30 |
|---|---|
| SK networks AI Camp - 평가 지표 (0) | 2024.08.26 |
| SK networks AI Camp - Machine Learning (2) | 2024.08.23 |
| SK networks AI Camp - Pandas EDA (0) | 2024.08.22 |
| SK networks AI Camp - Pandas 심화 (0) | 2024.08.21 |