(Colab에서 진행하며, 사용 데이터는 타이타닉 데이터를 사용합니다.)
1. 데이터 로드
import seaborn as sns
df = sns.load_dataset('titanic') # 타이타닉 데이터 받아오기
2. 데이터 조회
○ df.head(I) : 처음에 해당하는 데이터 I개를 출력
○ df.tail(I) : 끝에 해당하는 데이터 I개 출력
○ df.isnull() : Null 값인지 True, False로 확인
○ df.isnull().sum() : 컬럼별로 Null 값 확인
○ df.isnull().sum().sum() : 컬럼별로 Null 값을 확인한 것들의 합(즉, 전체 데이터의 Null 값의 수)
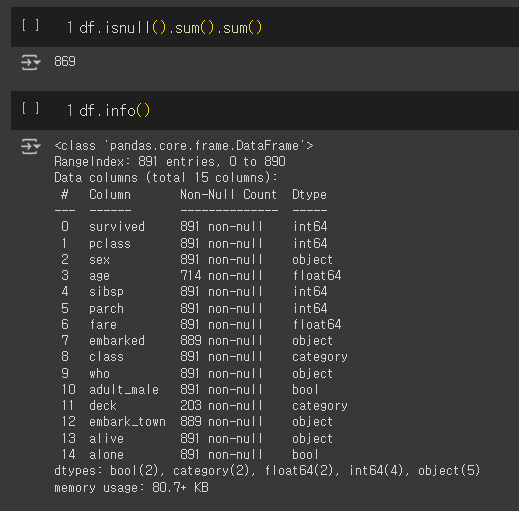
○ df.info() : 전체 수, nill 값 존재 유무, type 등에 대한 정보를 출력
# 처음 데이터 5개
df.head()
# 끝 데이터 5개
df.tail()
# DataFrame에서 Null 확인
df.isnull()
# 컬럼별로 Null 값 확인
df.isnull().sum()
# 전체 Null 갯수의 합 확인
df.isnull().sum().sum()
# 전체 수, null이 있는 컬럼, 데이터 타입
df.info()

3. 통계
○ df.count() : 갯수
○ df.sum() : 합
○ df.mean() : 평균
○ df.median() : 중위값
○ df.min() / df.max() : 최소, 최대값
○ df.abs() / df.std() / df.var() : 절댓값, 표준편차, 분산
df_number = df.select_dtypes(include=np.number)
df_object = df.select_dtypes(exclude=np.number)
df.shape, df_number.shape # 형태, (로우, 컬럼)
print(f'df.shape: {df.shape} / df_number.shape: {df_number.shape}')
print(f'df.shape: {df.shape} / df_number["age"].shape: {df_number["age"].shape}')
df_number.columns
df_number['age'].median() # Series의 통계값
df_number.mean() # DataFrame에서 사용하면 컬럼별 통계값
df_number.head()
df_number.mean(1) # 숫자1을 파라미터로 넣으면 로우 기준으로 통계값을 얻을 수 있음
df_number.max() - (df_number.std() + df_number.min()) # 가장 큰수 - (표준편차 + 가장 작은 수)
df_number.var() # 분산

○ value_counts()
df_object.columns # 컬럼 출력
df_object['class'].value_counts() # 갯수
df_object['embarked'].value_counts()
○ unique() / nunique() : 특정 열에서 고유한 값을 출력(중복 제거) / 해당 값의 갯수
df_object['class'].unique()
df_object['class'].nunique()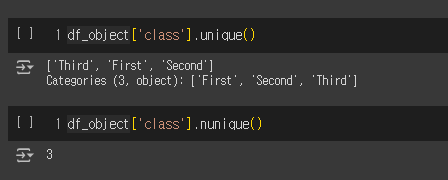
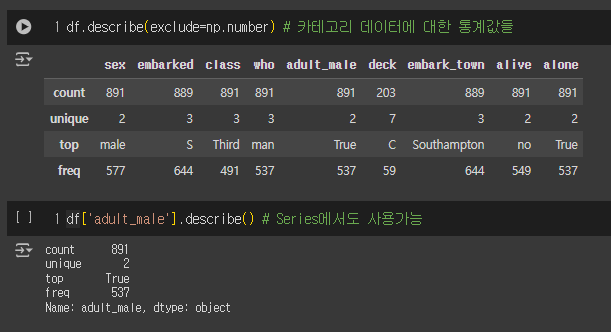
○ describe()
df.describe(include='all') # 수 & 카테고리 데이터 전부에 대한 통계값들
df.describe(include=np.number) # 수에 대한 통계값들
df.describe(exclude=np.number) # 카테고리 데이터에 대한 통계값들
df['adult_male'].describe() # Series에서도 사용가능
○ Map
x = pd.Series({'one':1,'two':2,'three':3})
y = pd.Series({1:'triangle',2:'square',3:'circle'})
x.map(y)
y.map(x)

df['sex'].unique()
df['sex'][:5]
replace_dict = {"male":1, "female":0}
df['sex'].map(replace_dict)[:5]
df['sex'][:5]
# replace_dict = {"male":1, "female":0}
df['sex'].map(lambda value: 1 if value == 'male' else 0)[:5]
○ apply() : 특정 연산을 열 또는 행 단위로 반복 적용할 때 자주 사용
● axis = 0 : 열 단위로 함수 적용
● axis = 1 : 행 단위로 함수 적용
● map과 달리 Matrix 연산도 가능
df_tmp = pd.DataFrame(np.arange(12).reshape(4,3),columns=['a','b','c'])
df_tmp['a'].apply(lambda x:x*2) # Series에 적용
df_tmp # df에는 변화 X
df_tmp.apply(lambda x:x.sum()) # column 합계
df_tmp.apply(lambda x:x.sum(), axis=1) # row 합계
df_tmp['row_sum'] = df_tmp.apply(lambda x:x.sum(), axis=1)
df_tmp['a+2'] = df_tmp.apply(lambda x:x['a']+2, axis=1)
def tmpFnc(a,b):
return a+b
# a와 b의 합을 'a+b' 컬럼에 값으로
df_tmp['a+b'] = df_tmp.apply(lambda x:tmpFnc(x['a'], x['b']), axis=1)
df_tmp


4. 집합
df.columns
select_cols = ['age', 'sex', 'pclass', 'fare', 'survived']
df_groupby = df[select_cols]
df_groupby.head()
○ pivot_table : 데이터 중에서 두 개의 열을 각각 행/열 인덱스로 사용해 데이터를 조회
○ 파라미터
● data : 데이터 프레임
● values : 데이터로 사용할 열
● index : 행으로 사용할 열
● columns : 열로 사용할 열
● aggfunc : 데이터 집계함수
○ 현재 데이터

# 평균
pd.pivot_table(df_groupby, index='sex', columns='pclass', values='age', aggfunc='mean')
# 최대 최소
pd.pivot_table(df_groupby, index='sex', columns='pclass', values='fare', aggfunc=['min', 'max'])
○ groupby
grouped = df_groupby.groupby(['sex']) # type : tuple
for i in grouped:
print(type(i))
for key, group in grouped:
print("* key", key)
print("* count", len(group))
print(group.head())
print('\n')
# 평균, 중위값
grouped.mean()
grouped.median()
group_female = grouped.get_group('female')
group_female.head()
# 여러 컬럼을 기준으로 집합
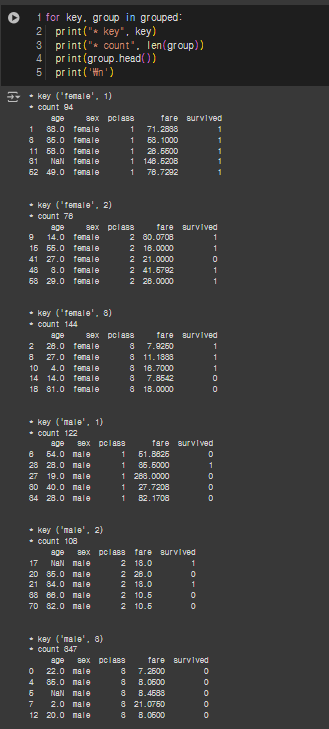
grouped = df_groupby.groupby(['sex','pclass'])
for key, group in grouped:
print("* key", key)
print("* count", len(group))
print(group.head())
print('\n')
grouped.mean()

○ agg
● DF나 Series에서 다양한 집계 작업을 수행할 때 사용
● 여러 집계 함수를 동시에 적용 | 사용자 정의 집계 함수 적용에 유용
# fare를 합계와 평균을 출력
df_groupby['fare'].agg(['sum', 'mean'])
# 성별 열을 기준으로 그룹화하여 GrouBy 객체가 됨
# → 그룹화된 데이터의 최소, 최댓값 출력
grouped = df_groupby.groupby(['sex'])
grouped.agg(['min', 'max'])
# fare 열은 최소, 최대값 / age 열은 평균값
agg_dict = {
'fare': ['min', 'max'],
'age': 'mean'
}
grouped.agg(agg_dict)
# 최대값에서 최솟값을 빼는 함수 구현
def min_max(x):
return x.max() - x.min()
grouped.agg(min_max)

○ transform()
: 그룹별로 매핑함수를 적용하긴 하지만, 그룹별로 집계하지 않고 원래 DF 형태로 반환
* 아래의 코드는 그룹별 데이터 조회 할때, 일반적 방법과 transform()을 이용한 방법
[일반적 방법]
● 각 그룹을 반복하면서 직접 z-score을 계산
● 평균/표준편차를 수동으로 계산 후 각 그룹에 대해 z-score을 수동 적용
● 결과 출력을 그룹별로 나눠져 있음
grouped = df_groupby.groupby(['pclass'])
age_mean = grouped.age.mean()
age_std = grouped.age.std()
for key, group in grouped.age:
group_zscore = (group - age_mean.loc[key]) / age_std.loc[key]
print("* origin :", key)
print(group_zscore.head(3))
print('\n')[transform 사용]
● 각 그룹에 대해 z-score을 자동 계산(transform은 그룹화된 데이터의 각 요소에 대해 함수를 적용)
● 원래의 데이터프레임 구조를 유지 + 평균/표준편차를 자동 계산하여 쉽게 z-score 계산 가능
● 데이터프레임의 구조를 유지하여 transform을 통해 z-score 결과를 원래 DF와 같은 구조로 반환
def z_score(x):
return (x - x.mean())/ x.std()
# tmp = 'age'
# df_transform = grouped[tmp]transform(z_score)
df_transform = grouped.age.transform(z_score)
print(df_transform.iloc[[1,3,6]])
print(df_transform.iloc[[9,15,17]])
print(df_transform.iloc[[0,2,4]])

기타 응용
○ 그룹별 나이 평균이 30미만인 그룹만 조회
test = grouped.filter(lambda x : x.age.mean() < 30)
print(test.head())
print(test['pclass'].unique())
○ 그룹별 통계 정보
grouped.apply(lambda x : x.describe())
합치기
○ merge()
● on : 두 데이터 프레임을 병합 시, 어떤 열을 기준으로 병합할지 지정하는 데 사용
해당 열의 공통된 부분만 나타나고, 두 데이터 프레임의 병합 기준 열의 이름이 다를 때는 사용 안함
* 병합 기준 열이 다른 경우 각각 다른 열을 병합기준으로 지정 가능
df1 = pd.DataFrame({
'ID': [1, 2, 3],
'Name': ['Alice', 'Bob', 'Charlie']
})
df2 = pd.DataFrame({
'Employee_ID': [1, 2, 4],
'Age': [25, 30, 22]
})
# df1의 'ID' 열과 df2의 'Employee_ID' 열을 기준으로 병합
merged_df = pd.merge(df1, df2, left_on='ID', right_on='Employee_ID')
print(merged_df)
""" 출력결과
ID Name Employee_ID Age
0 1 Alice 1 25
1 2 Bob 2 30
"""* 아래 코드의 경우 key를 기준으로 병합
left = pd.DataFrame(
{
"key": ["K0", "K1", "K2", "K3"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
}
)
right = pd.DataFrame(
{
"key": ["K0", "K1", "K2", "K3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}
)
result = pd.merge(left, right, on="key")
result
* key1과 key2를 기준으로 병합
left = pd.DataFrame(
{
"key1": ["K0", "K0", "K1", "K2"],
"key2": ["K0", "K1", "K0", "K1"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
}
)
right = pd.DataFrame(
{
"key1": ["K0", "K1", "K1", "K2"],
"key2": ["K0", "K0", "K0", "K0"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}
)
result = pd.merge(left, right, on=["key1", "key2"])
result
● how :두 데이터프레임을 병합할 때 사용할 조인 방식(병합 방식) 유형을 지정
- how = "inner" : default 값으로 두 데이터프레임의 공통된 값(교집합)만을 포함하여 병합
result = pd.merge(left, right, how="inner", on=["key1", "key2"])
result
- how = "outer" : 두 데이터 프레임의 모든 데이터를 포함(교집합 + 합집합) 즉, 모든 데이터
일치하지 않는 값은 NaN로 채워짐
result = pd.merge(left, right, how="outer", on=["key1", "key2"])
result
- how = "left" : 왼쪽(첫 번째) 데이터 프레임의 모든 데이터를 포함하여 병합
오른쪽 데이터프레임에서 일치하는 값이 없는 경우 NaN(결측치)로 채워짐
result = pd.merge(left, right, how="left", on=["key1", "key2"])
result
- how = "right" : 오른쪽 (2 번째) 데이터 프레임의 모든 데이터를 포함하여 병합
result = pd.merge(left, right, how="right", on=["key1", "key2"])
result
○ concat()
● 여러 데이터프레임이나 시리즈를 하나로 결합할 때 사용
● SQL의 UNION과 비슷한 역할
● axis = 0 : 행 방향(수직) 결합
● axis = 1 : 열 방향(수평) 결합
● ignore_index : 결합 후 인덱스 무시 여부(default : False)
● keys : 결합 후 계층적 인덱스 설정에 사용
df1 = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)
print(df1.shape)
df1.head()
# X컬럼에 [X0 ~ X3]까지 데이터로 넣음
# axis = 1 : 수평결합(열방향)
s1 = pd.Series(["X0", "X1", "X2", "X3"], name="X")
result = pd.concat([df1, s1], axis=1)
result
df4 = pd.DataFrame(
{
"B": ["B2", "B3", "B6", "B7"],
"D": ["D2", "D3", "D6", "D7"],
"F": ["F2", "F3", "F6", "F7"],
},
index=[2, 3, 6, 7],
)
print(df4.shape)
df4.head()
result = pd.concat([df1, df4], axis=1)
result
● inner join(교집합 방식)을 사용하여 df1과 df4를 열방향(axis=1)로 결합 → df1과 df4의 공통된 인덱스인 2, 3만 결합
result = pd.concat([df1, df4], axis=1, join="inner")
result
● 열방향으로(axis=1) df1과 df4를 모든 인덱스를 포함하는 outer join 방식으로 결합 → df1의 인덱스에 맞게 재정렬
df1의 인덱스를 기준으로 모든 인덱스를 포함하며 df4에 해당하는 인덱스가 없다면 NaN으로 채워짐
result = pd.concat([df1, df4], axis=1).reindex(df1.index)
result
● 결합을 하지만 인덱스를 무시하고 새로운 인덱스를 부여하며, 열 이름 정렬을 하지 않음
result = pd.concat([df1, df4], ignore_index=True, sort=False)
result
'Networks > 데이터 분석 및 AI' 카테고리의 다른 글
| SK networks AI Camp - Machine Learning (2) | 2024.08.23 |
|---|---|
| SK networks AI Camp - Pandas EDA (0) | 2024.08.22 |
| SK networks AI Camp - Pandas 기초 (0) | 2024.08.21 |
| SK networks AI Camp - Numpy 심화 (0) | 2024.08.21 |
| SK networks AI Camp - Machine Learning(용어 및 모듈 정리) (0) | 2024.08.20 |