Pandas: 데이터 처리와 분석을 위한 라이브러리
* 수많은 개발자들이 numpy의 alias는 np, pandas의 alias는 pd로 해줍니다.
import numpy as np
import pandas as pd
데이터 구조
○ Series : 1차원 구조로 되어 있는 데이터(벡터)
pd.Series(data=None, index=None, dtype=None, name=None, copy=False)
● Series 생성 : 스칼라 값인 경우에는 인덱스를 제공해야 한다.
data = {'a':1, 'b':2, 'c':3} # 딕셔너리
pd.Series(data=data, dtype=np.int16, name='dict')
# 스칼라 값인 경우 인덱스를 제공해야 함
pd.Series(5.0, index=['a', 'b', 'c', 'd', 'e'])
# np.random.randn: 가우시안 정규분포 난수
s = pd.Series(data=np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
슬라이싱/인덱스 : Numpy와 같이 슬라이싱/인덱스와 같은 작업
○ 시리즈명.median() : 중위값
○ 시리즈명.get('a', 'message') : 값이 a인 value를 반환(값이 없으면 message를 반환; 안 써주면 아무것도 반환 안됨)
s[s>s.median()], s.median()
'a' in s # S에 'a'인 key값이 있어서 true 반환
't' in s # S에 't'인 key값이 없어서 false 반환
s.get('rr') # 두 번째 인자가 없어서 아무것도 출력이 안됨
s.get('a', 'None') # 'a' 키가 존재하므로 'a'의 value가 출력
● 아래 코드 : 4번째, 2번째, 1번째 인덱스의 정보를 출력
lst = [4,2,1]
""" S
a -1.136282
b -0.274201
c 1.846150
d -0.157367
e -0.433985
dtype: float64
"""
a = s
c = s
s[lst], a[lst], c[lst]
● 시리즈명['K'] = V : 시리즈의 key가 K인 것의 value를 V로 변경
s['a'] = 1.5
s
● np.abs(시리즈명), np.exp(시리즈명) : 시리즈의 각 원소의 절댓값, 지수 함수 계산
s[[0,1,2]] = [0,1,2]
"""s
a 0.000000
b 1.000000
c 2.000000
d -0.157367
e -0.433985
dtype: float64
"""
np.abs(s), np.exp(s)
● 시리즈명.to_numpy() : numpy로 변환
DataFrame : 2차원 구조로 되어 있는 행렬 데이터
pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)
data = {
"one": pd.Series([1.0, 2.0, 3.0], index=["a", "b", "c"]),
"two": pd.Series([1.0, 2.0, 3.0, 4.0], index=["a", "b", "c", "d"]),
}
df = pd.DataFrame(data=data)
df
○ DataFrame.from_dict
data = {'col_1': [3, 2, 1, 0], 'col_2': ['a', 'b', 'c', 'd']}
pd.DataFrame.from_dict(data)
○ 데이터 변환
● pd.DataFrame.to_parquet()
- Apache Parquet 형식으로 저장
- 열지향 저장 방식으로 효율적인 데이터 저장과 쿼리 성능 제공
- 대량의 데이터에 대해 빠른 I/O 성능을 보임
- 데이터 스키마를 포함하여 데이터 구조를 유지
- 딥러닝, 머신러닝을 할 때 사용하는 것이 유
● pd.DataFrame.to_csv()
● pd.DataFrame.to_excel()
● pd.DataFrame.to_dict()
● pd.DataFrame.to_json()
df.to_dict()
df.to_dict('series')
df.to_dict('records')
df.to_json()
df.to_json(orient="records")
○ 컬럼 선택, 추가, 삭제
● del df명['컬럼명'] : 삭제
● df명.insert(index, '열이름', 내용) : index에 열이름을 넣고 colunm은 내용으로
data = {
"one": pd.Series([1.0, 2.0, 3.0], index=["a", "b", "c"]),
"two": pd.Series([1.0, 2.0, 3.0, 4.0], index=["a", "b", "c", "d"]),
}
df = pd.DataFrame(data=data)
# =================== 선택 ================
df['one'] # 'one' 컬럼 선택
df['three'] = df['one']+df['two'] # 'one'컬럼과 'two'컬럼의 값을 합한 'three'컬럼 생성
# =================== 추가 ================
df['one'] > 2 # 'one' 컬럼의 값이 2보다 크면 True, 작으면 False를 반환
list(df['one'] > 2) # 리스트 형태로 출력
df['flag'] = df['one'] > 2 # 'flag' 컬럼을 추가
# =================== 삭제 =================
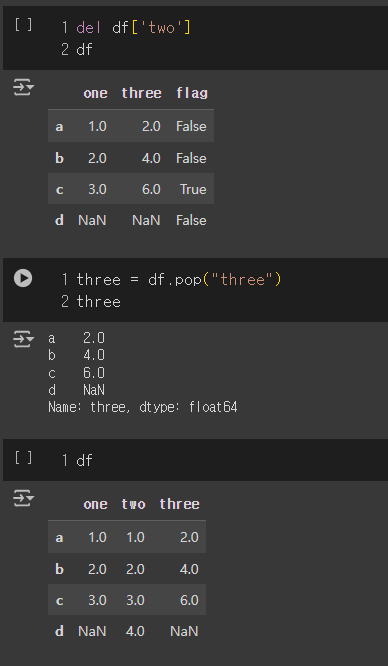
del df['two'] # 'two' 컬럼을 삭제
three = df.pop("three") # pop 연산하여 출력하고 삭제
# ================== 추가 활용 =============
df.insert(1, 'bar', df['one']) # 특정 위치에 열 추가
df['foo'] = 'bar'



Seaborn 라이브러리 : 데이터 시각화를 위한 파이썬 라이브러리
[Seaborn 주요 기능 및 함수]
- 상관 관계 시각화:
- seaborn.heatmap() : 상관 행렬을 색상으로 표현
- seaborn.pairplot() : 데이터의 여러 변수 간의 쌍별 관계를 시각화
- 분포 시각화:
- seaborn.histplot() : 데이터의 분포를 히스토그램으로 시각화
- seaborn.kdeplot() : 데이터의 커널 밀도 추정(Kernel Density Estimate)을 시각화
- seaborn.displot() : 분포를 시각화하는 복합적인 함수로, 히스토그램, KDE 등 다양한 형태를 지원
- 회귀 분석 시각화:
- seaborn.regplot() : 산점도와 회귀선을 시각화
- seaborn.lmplot() : 회귀선과 관련된 다양한 시각화
- 범주형 데이터 시각화:
- seaborn.boxplot() : 데이터의 분포를 박스 플롯으로 시각화
- seaborn.violinplot() : 데이터의 분포와 밀도를 시각화하는 바이올린 플롯을 제공
- seaborn.barplot() : 범주형 데이터의 평균값을 막대 그래프로 시각화
- 스타일과 색상:
- seaborn.set_style() : 기본 스타일을 설정 (e.g., 'whitegrid', 'darkgrid')
- seaborn.set_palette() : 색상 팔레트를 설정
e.g. seaborn을 이용하여 x,y 변수 간의 관계를 시각화하는 회귀선을 포함한 산점도 생성
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# 데이터 생성
data = pd.DataFrame({
'x': range(10),
'y': [2 * i + 1 for i in range(10)]
})
# 산점도와 회귀선 시각화
sns.regplot(x='x', y='y', data=data)
# 그래프 보여주기
plt.show()
마스킹을 이용한 다중 조건
○ & (= and) : 두 개 조건이 모두 참인 경우 True
○ | (= or) : 두 개 조건 중 하나 이상이 참인 경우 True
○ ~ (= not) : 거짓인 경우 True
mask = iris['sepal_length'] < 5.0
iris.loc[mask].head()
mask1 = iris['sepal_length'] < 5.0
mask2 = iris['sepal_width'] > 3.0
mask = mask1 & mask2
iris.loc[mask].head()
mask1 = iris['sepal_length'] < 5.0
mask2 = iris['sepal_width'] > 3.0
mask = mask1 | mask2
iris.loc[~mask].shape # (74, 5)
c1 = iris['sepal_length'] >= 5.0
c2 = iris['sepal_width'] <= 3.0
c = c1 & c2
iris.loc[c].shape # (74,5)

데이터 형식에 기반한 열 선택
iris.select_dtypes(include=np.number)
iris.select_dtypes(include='float64')
iris.select_dtypes(exclude=np.number)
'Networks > 데이터 분석 및 AI' 카테고리의 다른 글
| SK networks AI Camp - Pandas EDA (0) | 2024.08.22 |
|---|---|
| SK networks AI Camp - Pandas 심화 (0) | 2024.08.21 |
| SK networks AI Camp - Numpy 심화 (0) | 2024.08.21 |
| SK networks AI Camp - Machine Learning(용어 및 모듈 정리) (0) | 2024.08.20 |
| SK networks AI Camp - Numpy 기초 (0) | 2024.08.20 |