Numpy
: C언어로 구현된 Python 라이브러리, 벡터 및 행렬 연산에 있어 매우 편리한 기능을 제고
○ numpy.ndarray
● ndarray.ndim : Array 요소의 총 개수(= shape 요소의 곱)
● ndarray.shape : Array 크기를 나타내는 정수 튜플(행/열수)
● ndarray.size : Array 차원
● ndarray.dtype : Array 요소 데이터 타입

○ Numpy array vs Python list
● array : 모든 요소가 동질적이어야 함, list보다 빠르고 메모리를 적게 사용(코드 최적화 가능)
● list : 단일 목록 내에 다양한 데이터 유형 포함 가능
○ Numpy install
# CONDA
conda install numpy
# PIP
pip install numpy
Vector, Matrix
○ Vector
● 1차원 배열, Scalar가 연속적으로 여러 개 모여 있는 것
* Scalar : 단순하게 측정한 하나의 값
import numpy as np
lst = [1,2,3,4,5]
vector = np.array(lst)○ Matrix
● 2차원 데이터, 1차원 데이터가 여러 개 모여 있는 것
import numpy as np
lst = [
[1,2,3],
[4,5,6]
]
matrix = np.array(lst)
Numpy 기초
import numpy as np
lst = [1,4,5,6]
vector = np.array(lst)
vector
○ Python list를 이용한 배열
# python list를 이용한 배열
lst2 = [
[1,2,3],
[4,5,6]
]
arr2 = np.array(lst2)
arr2
arr2.size # 스칼라 전체 수
arr2.ndim # 차원
arr2.shape # 차원 모양(벡터 수, 스칼라 수)
arr2[1,2] # 스칼라 조회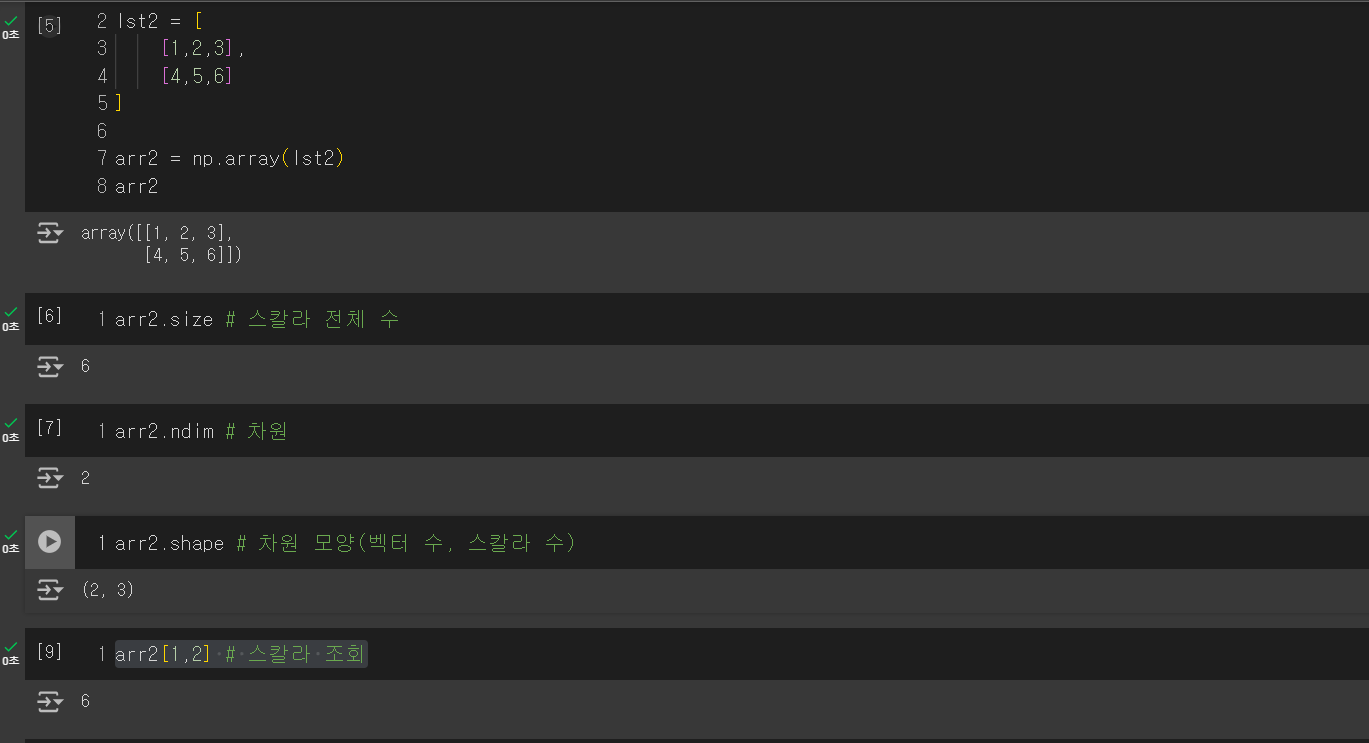
lst3 = [
[
[1,2,3],
[4,5,6]
],
[
[1,2,3],
[4,5,6]
],
[
[1,2,3],
[4,5,6]
],
[
[1,2,3],
[4,5,6]
]
]
arr3 = np.array(lst3)
arr3

arr3.size # 요소 총 개수(Scalar)
arr3.ndim # 차원 수(가로, Scalar 수)
arr3.shape # 차원 모양(Matrix 수(배열 갯수), Vector 수(배열에서 세로), Scalar 수(가로))
○ 특수한 배열 생성
● np.arrange(10) : 0부터 10개의 스칼라가 들어간 배열
● np.arrange(I, J) : 시작이 I부터 J까지(J 포함 안됨)
● np.zeros((I, J)) : I * J의 0 행렬 생성 I: 세로 수, J:가로 수
● np.ones((I, J)) : I * J의 1 행렬(유닛행렬) 생성
● np.full((I, J), K) : I * J의 Scalar가 K인 행렬 생성
● np.eye(I) : 단위행렬 생성
○ 배열 결합
● np.vstack((arr1, arr2)) : arr1부터 arr2까지 세로로 합침
arr1 = np.array([[1,1], [2,2]])
arr2 = np.array([[3,3], [4,4]])
arrv = np.vstack((arr1, arr2))
arrv
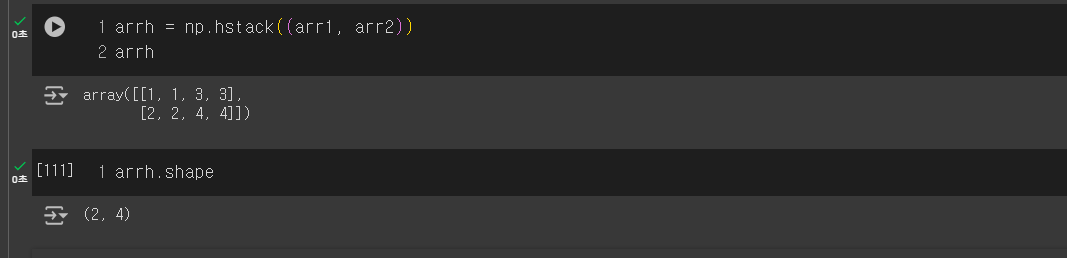
● np.hstack((arr1, arr2))
: arr1의 첫 번째와 arr2의 첫 번째 요소를 하나의 행(가로)으로 합치고 두 번째 요소들을 다음 열(세로)에 넣고 합침
○ 데이터 타입
● arr.astype(np.float32) : Scalar를 실수형으로 변환
● np.int8(arr) : Scalar를 int8형태로 변환
● np.array([1,2,3], dtype=np.bool_) : boolean 타입으로 변환
○ 슬라이싱/인덱싱
● 슬라이싱의 경우 파이썬에서 진행한 내용과 동일함
lst = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
arr = np.array(lst)
arr.shape● arr [0, :] = [11,12,13] : arr 인덱스가 0인 배열의 요소가 11, 12, 13으로 바뀜
● arr [0, :] = [1,2,3] arr [:,0]: arr의 인덱스가 0인 배열을 다시 바꾸고 배열의 0번째 Scalar를 반환
● arr [: , ::-1] : arr의 모든 요소를 -1부터 반환(반대로 출력)
● arr [::2, :] : arr의 처음 배열부터 2씩 증가하여(0번, 2번 배열만) 출력


○ 배열 조건 연산
arr = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
arr● arr [arr <5] : arr에서 5보다 작은 Scalar를 출력
● cond = (arr >= 5) arr [cond] : arr에서 5보다 크거나 같은 Scalar만 출력
● np.any(arry > 10) : 조건에 참이 하나라도 있으면 True
● np.all(arr >= 1) : 조건이 모두 참이면 True
● np.where(arr>5, I, J) : 5보다 크면(참) I 반환, 작으면(거짓) J 반환

○ np.clip(array, min, max)
● 배열 요소가 min보다 작으면 min으로 반환, max보다 크면 max 반환
● np.inf : 무한 / np.nan : 결측치
arr = np.array([np.inf, np.nan, 3,4,5,np.nan, 6, 7])
arr● np.isinf(arr) : inf값인 것을 찾기
● np.isnan(arr) : nan 값인 것을 찾기

○ 마스킹
lst = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
arr = np.array(lst)
arr.shape● mask = [True, False, True] : 1, 3번째의 값만 뽑기
mask = [True, False, True]
arr[: , mask]
○ Broadcasting

● 배열의 모양이 달라도 조건을 만족했을 때 작은 배열을 자동으로 큰 배열 크기에 맞춤
● 이 코드에서는 각 인덱스에 맞게 arr1과 arr2가 더해짐
arr1 = np.array([
[ 0.0, 0.0, 0.0],
[10.0, 10.0, 10.0],
[20.0, 20.0, 20.0],
[30.0, 30.0, 30.0]
])
arr2 = np.array([1.0, 2.0, 3.0])
arr1 + arr2
● 아래 코드는 arr2의 크기가 더 커서 오류가 발생
arr1 = np.array([
[ 0.0, 0.0, 0.0],
[10.0, 10.0, 10.0],
[20.0, 20.0, 20.0],
[30.0, 30.0, 30.0]
])
arr2 = np.array([1.0, 2.0, 3.0, 4.0])
arr1 + arr2

● 크기가 다른 경우 아래와 같이 조정해 주면 병합이 가능
arr1 = np.array([0.0, 10.0, 20.0, 30.0])
arr2 = np.array([1.0, 2.0, 3.0])
arr1[:, np.newaxis] + arr2

'Networks > 데이터 분석 및 AI' 카테고리의 다른 글
| SK networks AI Camp - Pandas EDA (0) | 2024.08.22 |
|---|---|
| SK networks AI Camp - Pandas 심화 (0) | 2024.08.21 |
| SK networks AI Camp - Pandas 기초 (0) | 2024.08.21 |
| SK networks AI Camp - Numpy 심화 (0) | 2024.08.21 |
| SK networks AI Camp - Machine Learning(용어 및 모듈 정리) (0) | 2024.08.20 |