기본 연산
○ 행렬 연산
● add(I, J), subtract(I, J), multiply(I, J), divide(I, J) : 각각 I+J, I-J, I*J, I/J 와 같은 결과
import numpy as np
data = np.array([1,2])
ones = np.ones(2, dtype=int) # 2차원의 요소가 1인 행렬 생성
data + ones, np.add(data, ones) # 두 개 같은 결과data - ones, np.subtract(data,ones) # 뺄셈 연산
data * data, np.multiply(data, data) # 곱셈 연산
data / data, np.divide(data, data) # 나눗셈 연산
● 변수명.sum(), 변수명.size : 각 요소(Scalar)의 합, 배열의 크기
● 변수명.reshape(I, J) : I * J로 배열을 변환
● 변수명.sum(axis=I) : *axis=I 다차원 배열에서 특정 차원을 나타냄. axis=0일 경우 첫 번째 축을 따라 연산 수행
e.g. 코드에서 arr([[1,2,3,4], [5,6,7,8])일 때 axis=0으로 하면 첫 번째 축은 배열 전체를 의미해서
1+5, 2+6, 3+7, 4+8이 되어 6,8,10,12가 출력
e.g. 코드에서 axis=1로 한다면 각 배열을 보고 계산하여 1+2+3+4, 5+6+7+8로 출력되어 10,26이 출력
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
arr = arr.reshape(2,4)
arr, arr.shape
arr.sum(axis=0), arr.sum(axis=1), arr.sum()
● max(), min() : 최대, 최소
data = np.array([1,2,3])
data.max(), data.min(), data.sum() # 3, 1, 6 출력
● 실수로 구성된 배열(예제) : 아래 코드의 출력값은?
arr = np.array([[0.45053314, 0.17296777, 0.34376245, 0.5510652],
[0.54627315, 0.05093587, 0.40067661, 0.55645993],
[0.12697628, 0.82485143, 0.26590556, 0.56917101]])
arr.sum(axis=1), arr.min(axis=1), arr.max(axis=1)- arr.sum(axis=1) : arr의 요소들을 합하는데 axis=1이 있으므로 각 배열들끼리 합하여 출력
(0.45053314 + 0.17296777 + 0.34376245 + 0.5510652),
(0.54627315 + 0.05093587 + 0.40067661 + 0.55645993),
(0.12697628 + 0.82485143 + 0.26590556 + 0.56917101) 가 출력
- arr.min(axis=1) : arr에서 가장 작은 값들을 출력
: 0.17296777, 0.05093587, 0.12697628 가 출력
- arr.max(axis=1) : arr에서 가장 큰 값들을 출력
: 0.5510652 , 0.55645993, 0.82485143
선형대수(벡터/행렬연산) 함수
○ Norm : 벡터의 크기를 나타냄
● L1 Norm : 두 개의 벡터를 빼고, 절댓값을 취한 뒤 합한 것
● L2 Norm : 두 개의 벡터의 각 요소를 빼고, 제곱하고 합한 뒤 루트 씌우기
● L1 Norm, L2 Norm을 코드로 구현
* 변수명.abs(), 변수명.sqrt() : 절대값, 루트
u = np.array([1,2,3,4,5])
# L1 Norm 함수 구현
def l1_norm(x):
x_norm = np.abs(x) # 절대값
return np.sum(x_norm) # 합
l1_norm(u)
# L2 Norm 함수 구현
def l2_norm(x):
x_norm = np.sum(x*x) # 제곱의 합
return np.sqrt(x_norm) # 루트
l2_norm(u)
np.linalg.norm(u,1), np.linalg.norm(u) # L1 norm, L2 norm● 추가 설명
- L1 distance(Manhattan distance)는 두 개의 고정된 벡터 사이에도 여러 개의 grid path가 발생 가능
- L2 distance(Euclidean distance)는 하나의 grid path(unique shortest path)만이 존재
- L2 norm은 제곱의 형태 So, outlier에 더욱 민감 → outlier가 있는 경우에는 L1 norm을 적용하는 것이 효과적
1. L1 거리(맨해튼 거리)
○ 직선으로만 갈 수 있는 경로 생각
○ 두 점 사이의 거리를 가로, 세로 방향으로만 계산(즉, L1거리 = 두 점 사이의 가로거리 + 세로거리)
e.g. 두 점 A(x1, y1), B(x2, y2)라면, L1 = |x2 - x1| + |y2 - y1|
○ 같은 거리라고 하더라도 우회하는 방법은 여러 가지
2. L2 거리(유클리드 거리)
○ 두 점을 직선으로 연결하는 가장 짧은 경로(최단 거리)
○ 두 점 사이의 직선거리 계산(즉, L2 거리 = 두 점 사이의 직선거리)
e.g. 두 점 A(x1, y1), B(x2, y2)라면
L2 거리 =

3. L2 Norm과 Outlier (L1 Norm과 비교)
○ L2 Norm
● L2 거리를 일반화한 개념
● 제곱을 하기 때문에 값이 큰 숫자(Outlier; 이상치)가 결과에 큰 영향을 미치기에 Outlier에 민감
○ L1 Norm
● L1 거리를 일반화한 개념
● 제곱 대신 절댓값을 사용하기에 제곱이 없어 Outlier의 영향이 비교적 작다.
● So, Outlier가 있는 경우 L1 Norm이 더 적합

벡터/행렬의 덧셈과 뺄셈
x = np.array([10,11,12])
y = np.array([0,1,2])
x + y, x - y # array([10,12,14]), array([10,10,10])x = np.array([[5, 6], [7, 8]])
y = np.array([[10, 20], [30, 40]])
z = np.array([[1, 2], [3, 4]])
x + y - z # array([[14, 24], [34, 44]])

벡터연산(내적)
○ 조건
● 두 벡터의 차원(길이)이 같아야 함
● 앞의 벡터 = 행벡터, 뒤의 벡터 = 열벡터
○ 특징
● 두 벡터의 각 요소끼리 곱의 합
● 결과값 = Scalar
○ X의 전치행렬(transpose matrix) : X^T
● '@' 연산자 : Numpy에서 행렬 곱셈(내적)을 수행하는 연산자
● np.dot(I, J) : 두 배열 I, J의 내적 계산
● I.dot(J.T) : dot메서드는 배열의 내적을 계산 y.T = y의 전치행렬이지만, 현재 y가 1차원 배열 So, 그대로 y
# 1차원 배열 내적
x = np.array([1,2,3])
y = np.array([4,5,6])
x @ y, np.dot(x,y), x.dot(y.T), y.dot(x.T) # 결과는 32로 모두 동일
○ 2차원 배열 내적
● 'x'는 2행 3열의 배열(= shape : (2,3) ) , 'y'는 3행 2열의 배열(= shape:(3,2))
● x @ y, x.dot(y)
- 결과 배열의 크기 : (2,3) * (3,2) = (2, 2)
- 첫 번째 행 계산
* 첫 번째 요소 : 1 * 6 + 2 * (-1) + 3 * 8 = 6 - 2 + 24 = 28
* 두 번째 요소 : 1 * 23 + 2 * 7 + 3 * 9 = 23 + 14 + 27 = 64
- 두 번째 행 계산
* 첫 번째 요소 : 4 * 6 + 5 * (-1) + 6 * 8 = 24 - 5 + 48 = 67
* 두 번째 요소 : 4 * 23 + 5 * 7 + 6 * 9 = 92 + 35 + 54 = 181
- 결과
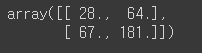
● y @ x, y.dot(x) :
- 결과 배열의 크기 : (3,2) * (2, 3) = (3, 3)
- 첫 번째 행 계산
* 첫 번째 요소 : 6 * 1 + 23 * 4 = 6 + 92 = 98
* 두 번째 요소 : 6 * 2 + 23 * 5 = 12 + 115 = 139
* 세 번째 요소 : 6 * 3 + 23 * 6 = 18 + 138 = 176
- 두 번째 행 계산
* 첫 번째 요소 : (-1) * 1 + 7 * 4 = -1 + 28 = 27
* 두 번째 요소 : (-1) * 2 + 7 * 5 = -2 + 35 = 33
* 세 번째 요소 : (-1) * 3 + 7 * 6 = -3 + 42 = 39
- 세 번째 행 계산
* 첫 번째 요소 : 8 * 1 + 9 * 4 = 8 + 36 = 44
* 두 번째 요소 : 8 * 2 + 9 * 5 = 16 + 45 = 61
* 세 번째 요소 : 8 * 3 + 9 * 6 = 24 + 54 = 78
- 결과

x = np.array([[1., 2., 3.], [4., 5., 6.]])
y = np.array([[6., 23.], [-1, 7], [8, 9]])
x @ y, x.dot(y) # array([[ 28., 64.], [ 67., 181.]])
y @ x, y.dot(x) # array([[ 98., 127., 156.], [ 27., 33., 39.], [ 44., 61., 78.]])
역행렬
: 행렬 A와 행렬 B를 곱했을 때, 단위행렬 I와 같으면, 행렬 B를 행렬 A의 역행렬

○ Y = inv(X) : inv(X)는 X에 대한 역행렬 So, X.dot(Y)로 곱하면 단위행렬이 리턴
from numpy.linalg import inv
X = np.array([[1,2,3],[1,0,0],[0,0,1]])
Y = inv(X) # X에 대한 역행렬
X.dot(Y)
난수
○ matplotlib.pyplot : Python에서 그래프를 보여주기 위해 사용하는 모듈
import matplotlib.pyplot as plt
np.random.seed(0)
plt.style.use('default')
plt.rcParams['figure.figsize'] = (6, 3)
plt.rcParams['font.size'] = 12○ np.random.rand(I) : 난수 I개 생성
# 난수 1000개 생성
a = np.random.rand(1000)
# 난수 10000개 생성
b = np.random.rand(10000)
# 난수 100000개 생성
c = np.random.rand(100000)
plt.hist(a, bins=100, density=True, alpha=0.5, histtype='step', label='n=1000')
plt.hist(b, bins=100, density=True, alpha=0.75, histtype='step', label='n=10000')
plt.hist(c, bins=100, density=True, alpha=1.0, histtype='step', label='n=100000')
plt.ylim(0, 2.5)
plt.legend()
plt.show()
○ np.random.randint(I, J, K) : I ~ K 범위에서 K개의 정수 생성
# a = (0, 10) 범위의 임의의 정수 1000개
a = np.random.randint(0, 10, 1000)
# b = (10, 20) 범위의 임의의 정수 1000개
b = np.random.randint(10, 20, 1000)
# c = (0, 20) 범위의 임의의 정수 1000개
c = np.random.randint(0, 20, 1000)
plt.hist(a, bins=100, density=False, alpha=0.5, histtype='step', label='0<=randint<10')
plt.hist(b, bins=100, density=False, alpha=0.75, histtype='step', label='10<=randint<20')
plt.hist(c, bins=100, density=False, alpha=1.0, histtype='step', label='0<=randint<20')
plt.ylim(0, 150)
plt.legend()
plt.show()
○ std * np.random.randn(I) + avg
● 표준정규분포로부터 샘플링된 난수 생성
● 표준편차가 std이고 평균이 avg인 정규분포의 난수 I개
# a = 평균과 표준편차가 각각 0,1인 정규분포의 난수 100000개
a = np.random.randn(100000)
# b = 평균과 표준편차가 각각 -1,2인 정규분포의 난수 100000개
b = 2 * np.random.randn(100000) - 1
# c = 평균과 표준편차가 각각 2,4인 정규분포의 난수 100000개
c = 4 * np.random.randn(100000) + 2
plt.hist(a, bins=100, density=True, alpha=0.5, histtype='step', label='(mean, stddev)=(0, 1)')
plt.hist(b, bins=100, density=True, alpha=0.75, histtype='step', label='(mean, stddev)=(-1, 2)')
plt.hist(c, bins=100, density=True, alpha=1.0, histtype='step', label='(mean, stddev)=(2, 4)')
plt.xlim(-15, 25)
plt.legend()
plt.show()
○ np.random.standard_normal(I)
● 표준정규분포를 갖는 난수 I 개 생성 (randn과 유사)
# 표준정규분포를 갖는 난수 1000개
a = np.random.standard_normal(1000)
# 표준정규분포를 갖는 난수 10000개
b = np.random.standard_normal(10000)
# 표준정규분포를 갖는 난수 100000개
c = np.random.standard_normal(100000)
plt.hist(a, bins=100, density=True, alpha=0.5, histtype='step', label='n=1000')
plt.hist(b, bins=100, density=True, alpha=0.75, histtype='step', label='n=10000')
plt.hist(c, bins=100, density=True, alpha=1.0, histtype='step', label='n=100000')
plt.legend()
plt.show()
○ np.random.normal(avg, std , I)
● 평균이 avg이고 표준편차가 std인 정규분포를 가지는 난수 I개 생성
# 평균 0, 표준편차 1인 정규분포를 갖는 난수 500개
a = np.random.normal(0, 1, 500)
# 평균 1.5, 표준편차 1.5인 정규분포를 갖는 난수 5000개
b = np.random.normal(1.5, 1.5, 5000)
# 평균 3.0, 표준편차 2.0인 정규분포를 갖는 난수 50000개
c = np.random.normal(3.0, 2.0, 50000)
plt.hist(a, bins=100, density=True, alpha=0.75, histtype='step', label=r'N(0, $1^2$)')
plt.hist(b, bins=100, density=True, alpha=0.75, histtype='step', label=r'N(1.5, $1.5^2$)')
plt.hist(c, bins=100, density=True, alpha=0.75, histtype='step', label=r'N(3.0, $2.0^2$)')
plt.legend()
plt.show()
○ np.random.random_sample(I)
● (0, 1) 범위의 샘플링된 임의의 실수 생성
● (a, b) 범위의 난수 생성법 : (b-a) * np.random.random_sample() + a
a = np.random.random_sample(100000)
b = 1.5 * np.random.random_sample(100000) - 0.75
c = 2 * np.random.random_sample(100000) - 1
plt.hist(a, bins=100, density=True, alpha=0.75, histtype='step', label='[0, 1)')
plt.hist(b, bins=100, density=True, alpha=0.75, histtype='step', label='[-0.75, 0.75)')
plt.hist(c, bins=100, density=True, alpha=0.75, histtype='step', label='[-1, 1)')
plt.ylim(0.0, 1.2)
plt.legend()
plt.show()

○ np.random.choice(r, I)
● 1차원 배열로부터 임의의 샘플 생성
● np.arange(r)에서 I개 생성
# np.arange(10)에서 1000개 생성
a = np.random.choice(10, 1000)
# [0, 1, 2, 4, 8]에서 1000개 생성
b = np.random.choice([0, 1, 2, 4, 8], 1000)
plt.hist(a, bins=100, density=False, alpha=0.75, histtype='step', label='Sample np.arange(10)')
plt.hist(b, bins=100, density=False, alpha=0.75, histtype='step', label='Sample [0, 1, 2, 4, 8]')
plt.ylim(0, 300)
plt.legend()
plt.show()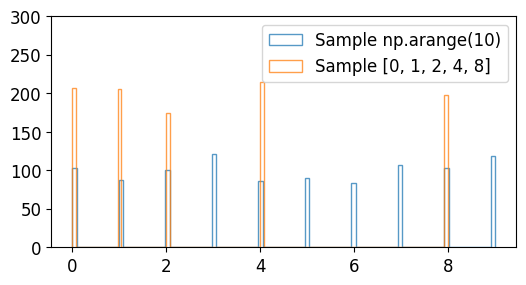
상수
○ np.inf : (양의) 무한대 부동 소수점
○ np.nan : 숫자가 아님
○ np.newaxis : 차원 추가
x_na = x[:, np.newaxis]
print(x_na.shape)
x_nax_na_na = x[:, np.newaxis, np.newaxis]
print(x_na_na.shape)
x_na_na

'Networks > 데이터 분석 및 AI' 카테고리의 다른 글
| SK networks AI Camp - Pandas EDA (0) | 2024.08.22 |
|---|---|
| SK networks AI Camp - Pandas 심화 (0) | 2024.08.21 |
| SK networks AI Camp - Pandas 기초 (0) | 2024.08.21 |
| SK networks AI Camp - Machine Learning(용어 및 모듈 정리) (0) | 2024.08.20 |
| SK networks AI Camp - Numpy 기초 (0) | 2024.08.20 |