머신 러닝 시스템 워크플로우
: 데이터 수집 → 점검 및 탐색 → 전처리 및 정제 → 모델링 및 훈련 → 평가 → 배포
○ 수집 : 머신러닝 학습에 필요한 데이터 수집
○ 점검 및 탐색 : 수집된 데이터의 구조, 노이즈 등 파악
(= 탐색적 데이터 분석(EDA; Exploratory Data Analysis) 단계)
○ 전처리 및 정제: 머신러닝 학습에 알맞게 데이터 정제 및 전처리
○ 모델링 및 훈련 : 머신러닝 알고리즘을 선택 및 전처리가 완료된 데이터를 이용하여 머신러닝 학습
○ 평가 : 테스트 데이터를 통해 모델 학습 평가, 평가가 좋지 않으면, 다시 머신러닝 학습을 진행
○ 배포 : 성공적으로 훈련이 된 것으로 판단 → 완성된 모델을 서비스에 적용하기 위해여 운영 배포를 진행

Feature Extraction
[사용 데이터]
1. 라이브러리 로드
# 구글 드라이브 연결(데이터 로드를 위함)
from google.colab import drive
drive.mount('/content/data')
# 데이터 분석에 사용할 라이브러리
import pandas as pd
import numpy as np
import logging
logging.getLogger('matplotlib.font_manager').setLevel(logging.ERROR)
# 데이터 시각화에 사용할 라이브러리
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
# 브라우저에서 바로 그려지도록
%matplotlib inline
# 그래프에 retina display 적용
%config InlineBackend.figure_format = 'retina'
# 유니코드에서 음수 부호설정
mpl.rc('axes', unicode_minus=False)2. 데이터 로드
# 데이터 경로에 맞게 만들던가 경로를 잘 지정해주기
DATA_PATH = "/content/data/MyDrive/ai_study/1. Machine Learning/data/"
df = pd.read_csv(DATA_PATH+"Titanic.csv")
df.shape, df.columns
df.columns = [col.lower() for col in df.columns] # 컬럼명 소문자로 변환
df.columns3. 데이터 분리
from sklearn.model_selection import train_test_split
SEED = 42
X_tr, X_te = train_test_split(df, random_state=SEED, test_size = 0.2)
X_tr = X_tr.reset_index(drop=True)
X_te = X_te.reset_index(drop=True)
X_tr.shape, X_te.shape
X_tr.head(), X_tr.columns
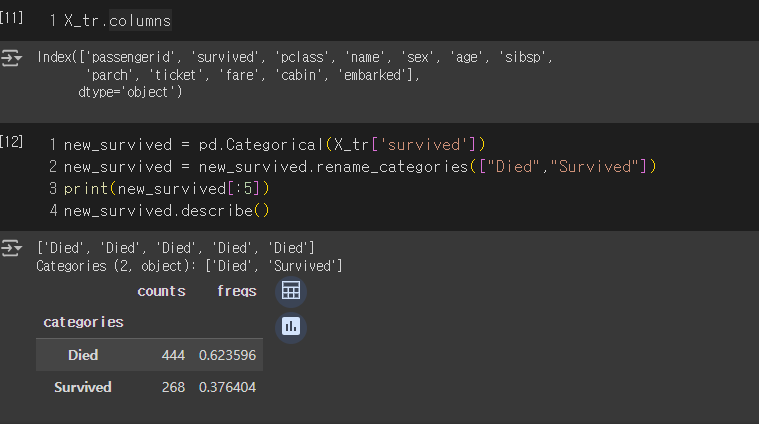
new_survived = pd.Categorical(X_tr['survived'])
new_survived = new_survived.rename_categories(["Died","Survived"])
print(new_survived[:5])
new_survived.describe()
4. 데이터 확인
X_tr.info(), X_tr.describe(include="all")
X_tr.describe(include=np.number), X_tr.describe(exclude=np.number)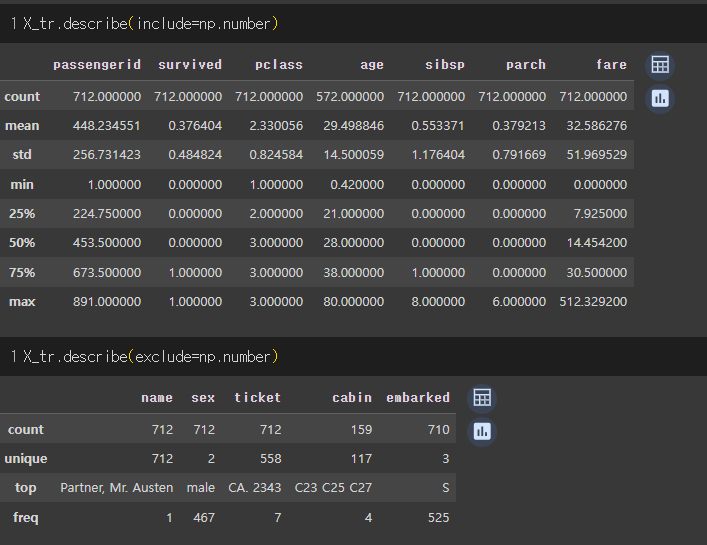
5. Data Cleaning
○ 필요 없는 데이터
X_tr['passengerid'].nunique(), X_tr.shape[0]
# passengerid는 전체 데이터가 unique하기 때문에 삭제
X_tr.drop('passengerid', axis=1, inplace=True)
X_te.drop('passengerid', axis=1, inplace=True)
X_tr.columns○ 결측치 정리 및 제거
(X_tr.isnull().sum() / X_tr.shape[0]).round(4).sort_values(ascending=False) # 각 걸럼별 결측치 비율
print(f'before: {X_tr.shape} / isnull().sum(): {X_tr.isnull().sum().sum()}')
# 결측치가 있는 행 제거 : X_tr.dropna(axis=0)
X_tr = X_tr.drop('cabin', axis=1)
X_te = X_te.drop('cabin', axis=1)
print(f'after: {X_tr.shape} / isnull().sum(): {X_tr.isnull().sum().sum()}')
X_tr['age'] = X_tr['age'].fillna(X_tr['age'].median())
X_te['age'] = X_te['age'].fillna(X_tr['age'].median())
embarked_mode = X_tr['embarked'].mode().values[0]
X_tr['embarked'] = X_tr['embarked'].fillna(embarked_mode)
X_te['embarked'] = X_te['embarked'].fillna(embarked_mode)
X_tr.isnull().sum().sum(), X_te.isnull().sum().sum()6. Feature Extraction : 기존 Feature에 기반하여 새로운 Feature 생성
○ 시작 전 데이터 타입 변환
why? 데이터 타입만 변환해 줘도 용량이 많이 줄어들게 됨 → 모델이 러닝 하는 데이터가 줄어드는 것이기에 효율성 증가
● 수치형 데이터 타입 변환
# 수치형 데이터 타입 변환
df_number = X_tr.select_dtypes(include=np.number)
df_number.columns, df_number.info()
# survived
X_tr["survived"] = X_tr["survived"].astype("int32")
X_te["survived"] = X_te["survived"].astype("int32")
# pclass
X_tr['pclass'].unique()
X_tr["pclass"] = X_tr["pclass"].astype("category")
X_te["pclass"] = X_te["pclass"].astype("category")
# age
X_tr["age"] = X_tr["age"].astype("int32")
X_te["age"] = X_te["age"].astype("int32")
# sibsp
X_tr['sibsp'].unique()
X_tr["sibsp"] = X_tr["sibsp"].astype("category")
X_te["sibsp"] = X_te["sibsp"].astype("category")
# parch
X_tr['parch'].unique()
X_tr["parch"] = X_tr["parch"].astype("category")
X_te["parch"] = X_te["parch"].astype("category")
# fare
X_tr["fare"] = X_tr["fare"].astype("float32")
X_te["fare"] = X_te["fare"].astype("float32")
● 범주형 데이터 타입 변환
X_tr["sex"] = X_tr["sex"].astype("category")
X_te["sex"] = X_te["sex"].astype("category")
X_tr["embarked"] = X_tr["embarked"].astype("category")
X_te["embarked"] = X_te["embarked"].astype("category")● 문자열 확인
df_object = X_tr.select_dtypes(include='object')
df_object.columns, df_object.head(), df_object.describe()
○ 공백 제거
X_tr["name"] = X_tr["name"].map(lambda x: x.strip())
X_tr["ticket"] = X_tr["ticket"].map(lambda x: x.strip())
X_te["name"] = X_te["name"].map(lambda x: x.strip())
X_te["ticket"] = X_te["ticket"].map(lambda x: x.strip())● 딕셔너리 형태로 값 넣기
why? Mr, Ms 등 호칭이 있으면(상위 계층?) 생존율이 높을 거라는 가설을 세움 → 이를 확인하기 위함
dict_designation = {
'Mr.': '남성',
'Master.': '남성',
'Sir.': '남성',
'Miss.': '미혼 여성',
'Mrs.': '기혼 여성',
'Ms.': '미혼/기혼 여성',
'Lady.': '숙녀',
'Mlle.': '아가씨',
# 직업
'Dr.': '의사',
'Rev.': '목사',
'Major.': '계급',
'Don.': '교수',
'Col.': '군인',
'Capt.': '군인',
# 귀족
'Mme.': '영부인',
'Countess.': '백작부인',
'Jonkheer.': '귀족'
}
dict_designation.keys()
# X_tr['name'].map(lambda x: x) ->
x = 'Andersson, Miss. Ebba Iris Alfrida '
x
x에 이름을 넣으면 그에 맞는 직함이 나오게 될 것
for key in dict_designation.keys():
result = 'unknown'
if key in x:
result = key
break
print(result)
● 함수로 만들기
: key값 확인 → key 값이 있으면 key(호칭) 값 리턴 <= 간단한 Feature를 추출하는 과정으로 볼 수 있다.
dict_designation = {
'Mr.': '남성',
'Master.': '남성',
'Sir.': '남성',
'Miss.': '미혼 여성',
'Mrs.': '기혼 여성',
'Ms.': '미혼/기혼 여성',
'Lady.': '숙녀',
'Mlle.': '아가씨',
# 직업
'Dr.': '의사',
'Rev.': '목사',
'Major.': '계급',
'Don.': '교수',
'Col.': '군인',
'Capt.': '군인',
# 귀족
'Mme.': '영부인',
'Countess.': '백작부인',
'Jonkheer.': '귀족'
}
def add_designation(name): # 호칭 함수
designation = "unknown"
for key in dict_designation.keys():
if key in name:
designation = key
break
return designation
X_tr['designation'] = X_tr['name'].map(lambda x: add_designation(x))
X_te['designation'] = X_te['name'].map(lambda x: add_designation(x))
X_tr.head()* unknown이 있는지 없는지 확인
# 트레인 데이터에unknown 확인
cond = X_tr['designation'] == "unknown"
X_tr.loc[cond].head()
X_tr[X_tr['designation'] == "unknown"].shape
# 테스트 데이터에unknown 확인
cond = X_te['designation'] == "unknown"
X_te.loc[cond].head()
○ 문자열 분리
● 이름의 성을 추출하기(검은색 네모 부분; 뒷부분)
- 사용한 방법 : Mr. 삭제[ replace() ] → ', ' 기준으로 나누기[ split() ] → last name 빈칸 제거하여 추출
- But 호칭이 다 있다는 가정이 있어야 함

def get_last_name(name):
last_name = None
try:
for key in dict_designation.keys(): # 이니셜을 다 조회하기
if key in name: # 이니셜이 있는지 확인하기
name = name.replace(key,'') # 이니셜을 제거하기
last_name = name.split(',')[1].strip() # 라스트 네임 추출하기
except:
pass
return last_name
X_tr['last_name'] = X_tr['name'].map(lambda x: get_last_name(x))
X_te['last_name'] = X_te['name'].map(lambda x: get_last_name(x))
X_tr[['name', 'last_name']].head()
● 첫 번째 이름(firt_name) 추출하기
X_tr['first_name'] = X_tr['name'].map(lambda x: x.split(',')[0].strip())
X_te['first_name'] = X_te['name'].map(lambda x: x.split(',')[0].strip())
X_tr.head()
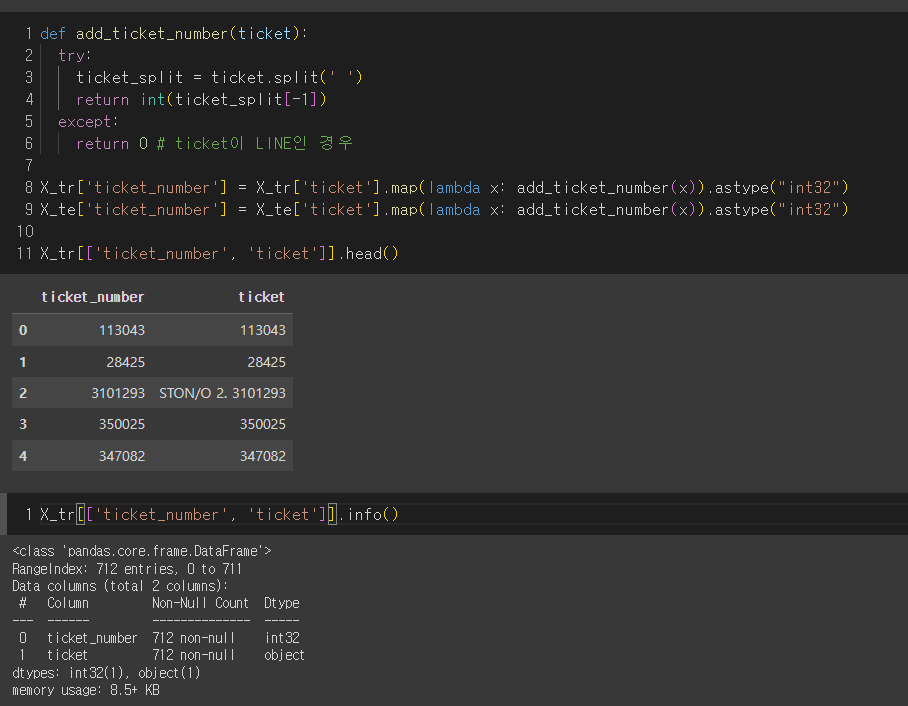
○ ticket number 나누기
X_tr['ticket']
def add_ticket_number(ticket):
try:
ticket_split = ticket.split(' ')
return int(ticket_split[-1])
except:
return 0 # ticket이 LINE인 경우
X_tr['ticket_number'] = X_tr['ticket'].map(lambda x: add_ticket_number(x)).astype("int32")
X_te['ticket_number'] = X_te['ticket'].map(lambda x: add_ticket_number(x)).astype("int32")
X_tr[['ticket_number', 'ticket']].head()
X_tr[['ticket_number', 'ticket']].info()
7. 집계
○ pivot table
● pclass 별로 요금의 평균 구하기
X_tr.head()
df_pivot = pd.pivot_table(X_tr, index='pclass', values='fare', aggfunc='mean').reset_index()
df_pivot.rename(columns = {'fare' : 'fare_mean_by_pclass'}, inplace = True)
df_pivot #.head()
● p_class 별 (survived의 평균, sibsp의 동행자 수 & parch의 동행자 수) 보기
agg_dict = {"survived" : "mean" ,
"sibsp" : "nunique",
"parch" : "nunique" }
df_groupby = X_tr.groupby("pclass").agg(agg_dict).reset_index()
df_groupby
# 그룹 바이하고 출력 할 때 이름을 바꿔주기
agg_dict = {"survived" : "mean" ,
"sibsp" : "nunique",
"parch" : "nunique" }
df_groupby = X_tr.groupby("pclass").agg(agg_dict).reset_index()
df_groupby.rename(columns = {'survived' : 'survived_by_pclass',
'sibsp' : 'len_sibsp_by_pclass',
'parch' : 'len_parch_by_pclass'}, inplace = True)
df_groupby
● merge를 통해 데이터 프레임에 새로운 값들 넣어주기
* 주의 : 항상 새로운 데이터는 train 데이터에 넣어줘야 함
print(f'before: {X_tr.shape}')
X_tr = pd.merge(X_tr,df_groupby,how="left",on="pclass")
X_te = pd.merge(X_te,df_groupby,how="left",on="pclass")
print(f'after: {X_tr.shape}')
X_tr.head()
● 나이대 확인(20대, 30대 등)
def sub_age(age):
return age // 10
X_tr['sub_age'] = X_tr['age'].map(lambda x: sub_age(x))
X_te['sub_age'] = X_te['age'].map(lambda x: sub_age(x))
X_tr[['age', 'sub_age']].head()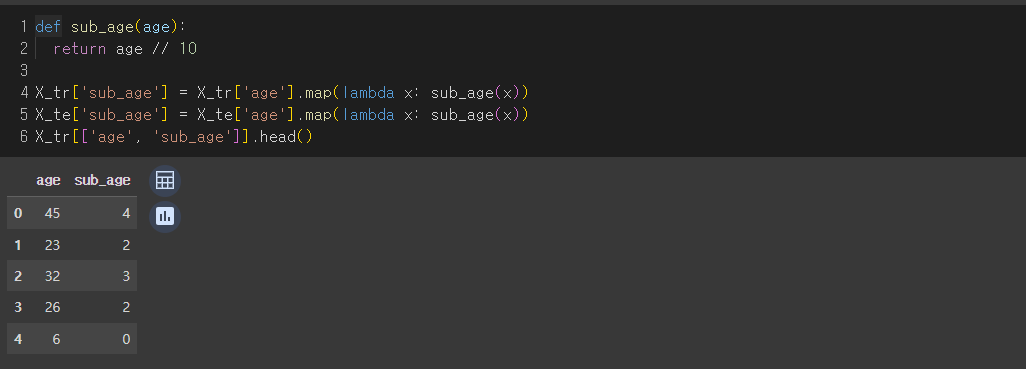
● 선실(범주형 데이터)을 합치기
* 데이터에 범주형을 무지성으로 붙여주면 모델이 규칙을 잘 찾는 경우가 있음
def add_sub_embarked(row):
return str(row['embarked']) + str(row['pclass']) + str(row['sibsp']) + str(row['parch'])
X_tr['sub_embarked'] = X_tr.apply(lambda row: add_sub_embarked(row), axis=1)
X_te['sub_embarked'] = X_te.apply(lambda row: add_sub_embarked(row), axis=1)
X_tr[['embarked', 'sub_embarked']].head()
8. 날짜 데이터(번외)
: 타이타닉 데이터는 날짜 정보가 없어서 시계열 데이터 분석을 할 수 없음. 따라서 시계열 분석을 위해 다른 데이터로 연습
DATA_PATH = "/content/data/MyDrive/ai_study/1. Machine Learning/data/"
df_cinemaTicket = pd.read_csv(DATA_PATH+"cinemaTicket_Ref.csv")
df_cinemaTicket.shape, df_cinemaTicket.info()
● object를 datetime으로 타입을 변경해 주기
df_cinemaTicket["date"] = pd.to_datetime(df_cinemaTicket["date"])
df_cinemaTicket.info()
● Feature 뽑을 수 있는 것 : 연/월/일, 주말, 분기, 공휴일, 분기, 365일 중 며칠이냐.... 등등
df_cinemaTicket["date"].dt.year[:5] # 연도
df_cinemaTicket["date"].dt.month[:5] # 월
df_cinemaTicket["date"].dt.day[:5] # 일
df_cinemaTicket["date"].dt.quarter[:5] # 분기
df_cinemaTicket["date"].dt.weekday[:5] # 요일: 0 ~ 6(월요일 ~ 일요일)
df_cinemaTicket["date"].dt.dayofyear[:5] # 연기준 몇일째인지..


● Progress Bar 다운(tqdm)
!pip install tqdm
from tqdm.auto import tqdm
# 예시
i=0
for i in tqdm(np.random.rand(10000000)):
i = i**2● tqdm 파라미터
- `iterable`: 반복자 객체
- `desc`: 진행바 앞에 텍스트 출력
- `total`: int, 전체 반복량
- `leave`: bool, default로 True (진행상태 잔상이 남음)
- `ncols`: 진행바 칼럼길이
- width값으로 pixel 단위로 보임
- `mininterval`, `maxinterval`: 업데이트 주기
- default mininterval=0.1 sec, maxinterval=10 sec
- `miniters`: Minimum progress display update interval, in iterations.
- `ascii`: True로 하면 `#`문자로 진행바가 표시됨
- `initial`: 진행 시작값. 기본은 0
- `colour`: 'blue', '#0000 ff' (헥스코드로도 입력 가능)
- `position`: 바 위치 설정. 여러 개의 바 관리할 때 지정
- Manual : with 구문을 사용해 tqdm을 수동 컨트롤, update()로 진행률을 증가시킴
iterable = ['a', 'b', 'c', 'd', 'e']
with tqdm(iterable,
total = len(iterable), ## 전체 진행수
desc = 'Description', ## 진행률 앞쪽 출력 문장
ascii = ' =', ## 바 모양, 첫 번째 문자는 공백이어야 작동
leave = True, ## True 반복문 완료시 진행률 출력 남김. False 남기지 않음.
) as pbar:
for c in pbar:
pbar.set_description(f'Current Character "{c}"') ## 또는 pbar.desc = f'Current Character "{c}"'
time.sleep(0.2)iterable = ['a', 'b', 'c', 'd', 'e']
pbar = tqdm(iterable,
total = len(iterable), ## 전체 진행수
desc = 'Description', ## 진행률 앞쪽 출력 문장
ascii = ' =', ## 바 모양, 첫 번째 문자는 공백이어야 작동
leave = True, ## True 반복문 완료시 진행률 출력 남김. False 남기지 않음.
)
for c in pbar:
pbar.set_description(f'Current Character "{c}"') ## 또는 pbar.desc = f'Current Character "{c}"'
time.sleep(0.2)
pbar.close() # with를 사용하지 않은 경우에는 꼭 close()를 해야함!
● 이중 루프의 경우
import time
for outer in tqdm([10, 20, 30, 40, 50], desc='outer', position=0): ## 출력되는 라인을 나타내는 position을 0 으로 두고
for inner in tqdm(range(outer), desc='inner', position=1, leave=False): ## 안쪽 루프의 진행률 출력은 그 아랫줄인 position = 1 로 설정하는 것이다.
time.sleep(0.01)● with Jupyter Notebook
from tqdm.notebook import tqdm
import time
for outer in tqdm([10, 20, 30, 40, 50], desc='outer', position=0):
for inner in tqdm(range(outer), desc='inner', position=1, leave=False):
time.sleep(0.01)● with pandas
tqdm.pandas() # 판다스에서 progress_apply 메소드를 사용할수 있게 된다.
import time
def do_apply(x):
time.sleep(0.01)
return x
tmp = df.progress_apply(do_apply,axis = 1)'Networks > 데이터 분석 및 AI' 카테고리의 다른 글
| SK networks AI Camp - 평가 지표 (0) | 2024.08.26 |
|---|---|
| SK networks AI Camp - Data Encoding (0) | 2024.08.23 |
| SK networks AI Camp - Pandas EDA (0) | 2024.08.22 |
| SK networks AI Camp - Pandas 심화 (0) | 2024.08.21 |
| SK networks AI Camp - Pandas 기초 (0) | 2024.08.21 |